
2018년 제안 된 새로운 워드 임베딩 방법론 중 하나,
ELMo라는 이름은 새서미 스트릿이라는 미국 인형극 캐릭터의 이름이기도 한데,
BERT 모델과 같이 캐릭터를 기반으로 이름을 짓는 경우가 다분하다.ELMo는 Embeddings from Language Mode의 약자로서 직관적으로 해석하자면
"언어 모델을 통한 임베딩"이라고 할 수 있는데 엘모의 가장 큰 특징은 사전훈련 모델을 사용한다는 것이 특정임
1. Abstract
이 논문은 단어의 구문적(Syntactic) 및 의미적(Semantic) 특성을 포착하고, 다양한 언어적 맥락에 따라 단어의 의미가 어떻게 변하는지를 모델링하는 새로운 형태의 심층 문맥화된 단어 표현을 제안함
1-1. 모델 구조
- 양방향 언어 모델(biLM)의 내부 상태를 기반으로 단어 벡터를 학습.
- 전체 입력 문장을 고려한 문맥 의존적(Contextualized) 단어 벡터 제공.
1-2. ELMo
- ELMo 벡터는 biLM의 모든 내부 계층을 선형 결합해 생성됨.
- 기존 단일 계층 사용 방식보다 더 정교하고 풍부한 표현 가능.
1-3. 핵심 성능
- ELMo는 질문 응답(Question Answering), 텍스트 함의(Textual Entailment), 감정 분석(Sentiment Analysis) 등 6가지 NLP 태스크에서 최첨단 성능 달성.
- 최대 20% 상대 오류 감소 달성.
1-4. 중요성
- 사전 훈련된 양방향 언어 모델의 내부 계층 정보를 노출하여 각 태스크가 가장 적합한 정보를 선택할 수 있도록 함.
2. Introduction
배경 및 문제의식
- 기존의 단어 임베딩 기법(예: Word2Vec, GloVe)은 단어의 구문적(Syntax) 및 의미적(Semantics) 특성을 일부 포착하지만, 다의어(polysemy)나 문맥(Contextual Variation)을 충분히 표현하지 못함.
기존 접근법의 한계
- 전통적인 단어 벡터는 단어별 고정된 표현(Fixed Representations)만 제공.
- 최근 접근법(CoVe, context2vec)은 문맥을 반영하지만 주로 LSTM 최상위 계층의 출력을 사용하며, 내부 계층의 정보를 충분히 활용하지 못함.
ELMo의 등장
- ELMo(Embeddings from Language Models)는 심층 양방향 언어 모델(biLM)을 기반으로 학습된 벡터를 제공.
- 모든 LSTM 계층의 출력을 선형 결합하여 각 태스크에 최적화된 벡터를 생성.
주요 특징
- 다중 계층 정보 통합: 높은 계층은 의미적(Semantic) 특성, 낮은 계층은 구문적(Syntactic) 특성을 잘 포착.
- 태스크별 최적화: 각 태스크가 필요로 하는 정보의 중요도를 스스로 학습할 수 있음.
핵심 성과
- ELMo를 기존 NLP 모델에 통합했을 때 6가지 대표 NLP 태스크(예: 질문 응답, 텍스트 함의, 감정 분석)에서 최첨단 성능 달성.
기여:
- 이 연구는 ELMo가 다양한 NLP 태스크에 손쉽게 통합될 수 있음을 보여주며, NLP 모델의 성능을 획기적으로 개선할 수 있는 가능성을 제시.
3. ELMo: Embeddings from Language Models
- 핵심 개념:
- ELMo는 양방향 언어 모델(biLM)을 기반으로 단어 벡터를 학습.
- 단어 표현은 전체 입력 문장(context)을 고려해 동적으로 생성됨.
- Bidirectional Language Models (biLM):
- 순방향(Forward) 및 역방향(Backward) LSTM을 사용하여 문맥을 인코딩.
- 모든 계층의 출력을 활용해 깊은 문맥적 표현을 생성.
- ELMo 벡터 계산:
- biLM의 모든 은닉 상태를 선형 결합하여 ELMo 벡터 생성.
- 각 태스크에 맞게 가중치를 학습하며 최적의 표현을 제공.
- 태스크 통합:
- ELMo 벡터는 기존 NLP 모델의 입력 또는 은닉층에 쉽게 통합 가능.
- 태스크별 최적화로 성능 향상을 달성.
- 훈련:
- 대규모 말뭉치에서 biLM을 사전 훈련(pre-training)한 후, 필요한 경우 도메인 특화 미세 조정(fine-tuning) 수행.
ELMo는 기존 단어 임베딩 모델보다 더 깊고 풍부한 문맥적 표현을 제공하여 다양한 NLP 태스크에서 성능을 크게 향상시킴.
Foward

Backward

주요 특이점

\(2L + 1\) \(Representations\)
- 각 단어 토큰에 대해 입력 임베딩과 L개의 양방향 LSTM(hidden states) 출력을 사용해 2L + 1개의 표현을 생성
- 그런 다음, 이 표현들을 Softmax로 가중치를 학습하여 최종적으로 하나의 벡터로 통합.
- 입력 임베딩(Token Embedding) \(x_k^{LM}\)
- 순방향 LSTM 은닉 상태 (Forward Hidden States) \(\overrightarrow{h}_{k,j}^{LM}\)
- \( k \): 단어 토큰의 위치
- \( j \): LSTM 계층의 인덱스
- 역방향 LSTM 은닉 상태 (Backward Hidden States) \(\overleftarrow{h}_{k,j}^{LM}\)
- \( k \): 단어 토큰의 위치
- \( j \): LSTM 계층의 인덱스
- 이 모든 상태를 합치면 2L + 1개의 표현이 만들어짐.
- ELMo 벡터 생성:
$$
ELMo_k = \sum_{j=0}^{L} s_j h_{k,j}^{LM}
$$ - \( L \) : LSTM 계층의 수
- \( h_{k,j}^{LM} \) : biLM의 \(j\)번째 계층에서 얻은 단어 \(k\)의 표현
- \( s_j \) : 각 계층의 가중치 (Softmax로 정규화됨)
- 의미:
- 낮은 계층: 구문적(Syntactic) 정보
- 높은 계층: 의미적(Semantic) 정보
- 이 두 정보를 모두 통합하여 최적의 문맥적 표현을 제공함
- 의미:
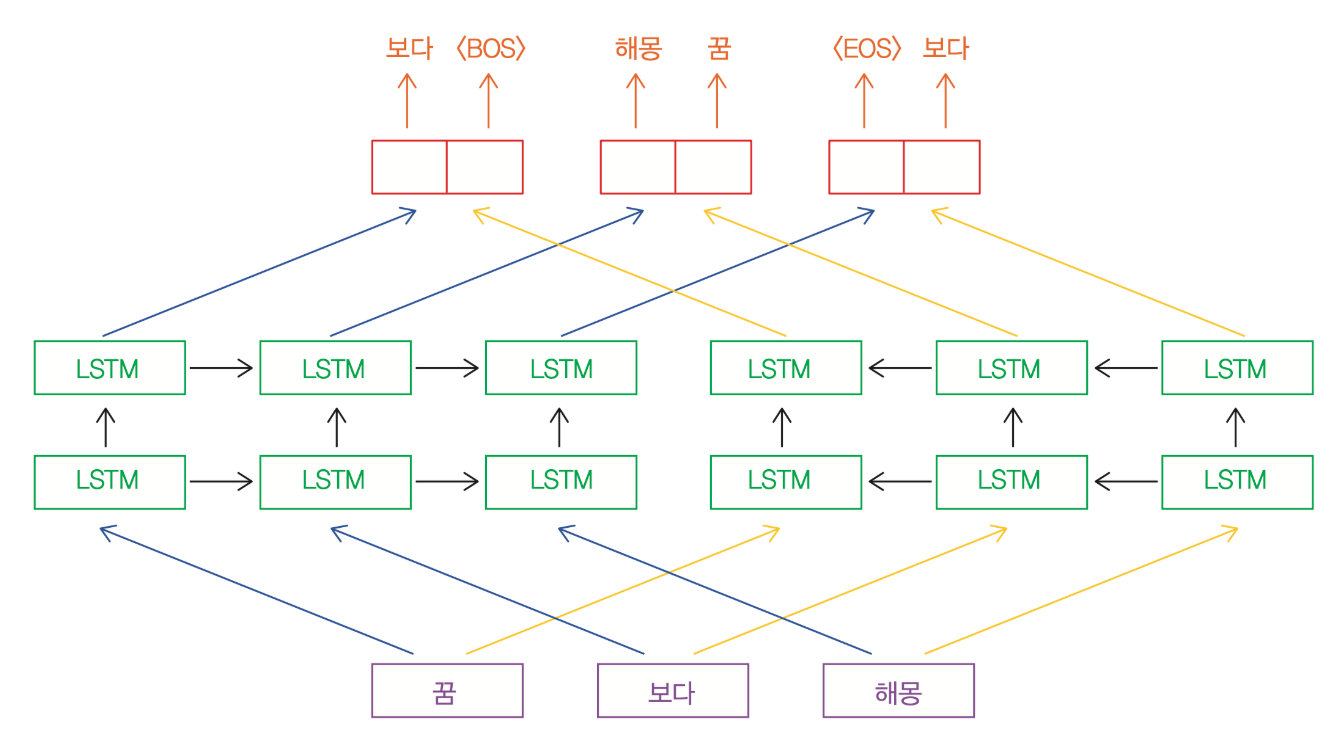
4. Pre-trained Bidirectional Language Model Architecture
- 모델 구조:
- ELMo는 2층 biLSTM 구조를 사용하며, 각 LSTM 층에는 4096 유닛과 512차원 투영(projection)이 포함됨.
- 첫 번째와 두 번째 LSTM 층 사이에 잔차 연결(Residual Connection)이 추가됨.
- 입력 표현:
- 2048개의 문자 n-그램(Character n-gram)을 사용하여 입력 토큰을 벡터화.
- 두 개의 Highway Network 층과 선형 투영층을 통해 512차원 임베딩으로 변환.
- 훈련:
- 1 Billion Word Benchmark로 훈련되었으며, 10 에포크(Epochs) 동안 진행.
- 훈련 후, 전방향 및 역방향 퍼플렉서티(Perplexity) 평균은 약 39.7.
- 파인 튜닝 (Fine-tuning):
- 도메인 특화 데이터로 추가 미세 조정하여 퍼플렉서티를 감소시키고 성능을 향상시킴.
핵심: ELMo의 biLM은 대규모 말뭉치를 활용해 사전 훈련되었으며, 입력을 문자 단위로 처리해 **어휘 외 단어(OOV)**에 강건한 성능을 보임.
5. Evaluation
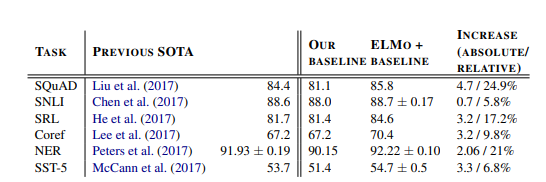
주요 내용:
- 태스크: SQuAD, SNLI, SRL, Coreference Resolution, NER, SST-5
- 평가 지표: 정확도(Accuracy), F1 점수 등
- 결과: 모든 태스크에서 기존 모델 대비 성능 향상
- 상대적 오류 감소: 6%~20%
6. Conclusion
이 논문은 ELMo(Embeddings from Language Models)가 다양한 NLP 태스크에서*최첨단 성능(SOTA)을 달성함을 보여줌.
ELMo는 양방향 LSTM(biLSTM)의 모든 계층 출력을 선형 결합하여 문맥 의존적(Contextualized) 단어 표현을 생성함.
이를 통해 기존 임베딩 기법보다 더 풍부한 구문적(Syntactic) 및 의미적(Semantic) 정보를 제공함.
ELMo는 다양한 NLP 아키텍처에 쉽게 통합될 수 있으며, 각 태스크에 최적화된 표현을 학습해 상당한 성능 개선을 이룩함.
'딥러닝, 논문 리뷰' 카테고리의 다른 글
| [딥러닝 논문리뷰] Seq2Seq 메커니즘 Sequence - 2 (1) | 2025.01.10 |
|---|---|
| [딥러닝, 논문리뷰] Meta - Memory Layers at Scale (0) | 2025.01.04 |
| [딥러닝, 논문리뷰] Efficient Estimation of Word Representations in Vector Space(Word2Vec) - 2 (3) | 2025.01.01 |
| [딥러닝] BCE, MSE를 단순 분류, 회귀 문제에서만 사용했다고? - Deep Dive 1편(Loss Function편) (4) | 2025.01.01 |
| [딥러닝] Word2Vec 논문 리뷰 전 분석 - 1 (4) | 2025.01.01 |