https://arxiv.org/abs/2502.13347v1
Craw4LLM: Efficient Web Crawling for LLM Pretraining
Web crawl is a main source of large language models' (LLMs) pretraining data, but the majority of crawled web pages are discarded in pretraining due to low data quality. This paper presents Crawl4LLM, an efficient web crawling method that explores the web
arxiv.org
1. Abstract
Craw4LLM은 대형 언어 모델(LLM)의 사전 훈련을 위한 더 효율적인 웹 크롤링 방법을 제안하는 연구, 기존의 웹 크롤러는 그래프 연결성(PageRank, Indree 등)을 기반으로 크롤링 하지만 위 방법은 LLM 훈련에 적합한 데이터를 효과적으로 찾지 못한다고 논문에서는 설명합니다.
이에 따라서, 전체 크롤링 된 90% 이상의 데이터들이 폐기 되는 비 효율성의 문제가 발생한다고 하네요
그렇기에 Craw4LLM은 기존 방식과 다르게, LLM 사전 훈련에 기여하는 정도(Pretraining Influence Score)를 기반으로 웹페이지의 중요도를 평가하여, 훈련에 유용한 데이터만을 우선적으로 크롤링하는 방법을 제안합니다.

2. Introduction
LLM 사전 훈련을 위한 웹 데이터와 기존 크롤링 방식의 비효율성
1. 웹데이터의 중요성을 강조
- 웹 데이터는 방대하고 다양한 주제를 내포, LLM 사전 훈련의 주요한 데이터 소스로 활용
- 이러한 데이터는 인간의 지식과 현실 세계 정보를 반영하는 방대한 말뭉치(코퍼스라고도 하죠?)를 제공
- LLM 훈련을 위한 대표적인 대규모 웹 크롤링 데이터셋으로 Common Crawl이 있으며, 이는 수십억 개의 웹페이지와 테라바이트(TB) 단위의 데이터를 포함
2. 기존 웹 크롤링 방식의 문제점
- 데이터 필터링으로 인한 비 효율성
- 웹에서 수집한 로우데이터 중 90% 이상이 LLM 훈련에 사용되지 못하고 폐기되는 문제
- 이는 비효율적인 웹 크롤링 방식이 LLM에 적합하지 않은 데이터를 지나치게 많이 수집하기 때문이라고 설명
- 기존 크롤링 방식: 그래프 연결성 기반(PageRank, Indegree 등)
- 기존 크롤러(Common Crawl 등)는 웹페이지의 연결성(graph connectivity)을 기준으로 페이지의 우선순위를 결정함
- 대표적인 방식 :
- PageRank (Page et al., 1999; Cho et al., 1998): 링크 수 및 연결 구조를 기반으로 중요도를 평가
- Harmonic centrality (Boldi & Vigna, 2014): 네트워크 상에서 페이지의 중심성을 고려하여 중요도 평가
- Indegree (Fortunato et al., 2008): 인링크가 많은 문서를 우선적으로 크롤링
- 문제점 : LLM의 훈련과의 불일치
- 그래프 연결성이 높은 문서가 LLM 훈련에 반드시 유용한 방법은 아님
- 예를 들어, 광고 페이지, 인기 있지만 정보 가치가 낮은 페이지도 링크가 많아 높은 PageRank 점수를 받을 수 있음.
- 결과적으로 LLM 훈련에 불필요한 데이터까지 크롤링되고, 이후 대부분 폐기됨.
- 불필요한 크롤링 증가 → 웹사이트 부담 증가
- 과도한 데이터 크롤링은 서버 트래픽을 증가시키고, 웹사이트 운영자에게 불필요한 부담을 줌
- 또한 법적 및 윤리적 문제(저작권, 데이터 공정 사용 이슈 등)를 초래할 수 있음.
이러한 문제를 해결 하기 위해서 필자는 위 논문을 통해 Craw4LLM이라는 새로운 방식은 제안해냄
CRAW4LLM: 기존 웹 크롤링의 한계를 극복하는 새로운 접근 방식
- Craw4LLM의 핵심 아이디어:
- 웹 페이지의 LLM 훈련 기여도를 기반으로 크롤링 우선순위 결정
- LLM 훈련에 도움이 되는 문서를 더 많이 크롤링 하여 더 적은 데이터로도 기존과 같은 성능을 유지
- 작동 방식
- 크롤링의 이터레이션(반복 과정)에서 새롭게 발견된 문서들을 평가
- 데이터 필터링을 위한 파이프라인을 기반으로 각 문서에 "LLM 훈련 기여 점수를 할당"
- 즉, LLM 훈련에 적합한 문서일수록 높은 점수를 받음
- 가장 높은 점수를 받은 문서를 우선적으로 사용 하여 추가 문서 탐색
- 즉, PageRank 같은 그래프 연결성 대신 "LLM 훈련 기여도"를 기준으로 크롤링 경로를 결정
- Figure 1에서 보여주듯이, 기존 크롤러와는 다른 방식으로 웹 그래프를 탐색함
- 크롤링의 이터레이션(반복 과정)에서 새롭게 발견된 문서들을 평가
결과적으로 기존 방식(PageRank, Indree)보다 훨씬 적은 데이터 크롤링으로도 높은 품질의 데이터 확보 가능
3. 실험 및 성능 평가 (Large-Scale Crawling Simulations)
실험 환경:
- ClueWeb22-A: 9억 개(900M)의 영어 웹페이지로 구성된 대규모 웹 그래프
- CRAW4LLM과 기존 크롤러 성능 비교
- 기존 크롤러: 1×, 2×, 4× 크롤링 후 데이터 선택 적용
- CRAW4LLM: 1×만 크롤링하여 성능 비교
- 결과
- CRAW4LLM은 기존 크롤러보다 훨씬 적은 데이터(21% URL 크롤링)로도 동일한 성능 달성
- 기존 크롤러가 동일한 성능을 달성하려면 최대 4배(4×)의 데이터를 크롤링해야 함
- CRAW4LLM은 전체 웹 그래프를 크롤링하는 "Oracle Selection"의 95% 성능을 단 2.2%의 데이터로 달성

상기 그래프는 LLM 사전 훈련 기여 점수(Pretraining Influence Score)와 기존 그래프 연결성 지표(PageRank 및 Indegree) 간의 상관관계를 분석한 결과를 보여주는 그래프
- 분석 목표
- 기존 웹 크롤링 방식(예: PageRank, Indegree 기반 크롤링)이 LLM 훈련에 적합한 데이터를 선별하는 데 얼마나 효과적인가?
- Craw4LLM에서 사용하는 Pretraining Influence Score와 기존 방식(PageRank, Indegree)의 상관관계를 비교하여 기존 방식의 한계를 확인
- Figure의 내용
- Pretraining Influence Score vs. Indegree (왼쪽 그래프)
- X축: 웹페이지의 Indegree(인링크 수, 즉 다른 웹페이지에서 해당 웹페이지로 연결된 링크 수)
- Y축: 해당 웹페이지의 Pretraining Influence Score (LLM 훈련에서의 기여도 점수)
- 음의 상관 관계로 보임
- Indegree가 높은 페이지(즉, 많이 링크된 페이지)라고 해서 반드시 LLM 훈련에 적합한 것은 아님.
- 오히려 Indegree와 Pretraining Influence Score 간에는 거의 상관관계가 없음(또는 약한 음의 상관관계).
- 이는 많이 링크된 페이지가 꼭 LLM 훈련에 가치 있는 데이터를 포함하는 것은 아니라는 것을 의미함.
- PageRank vs. Indegree (오른쪽 그래프)
- X축: 웹페이지의 Indegree(인링크 수)
- Y축: 해당 웹페이지의 PageRank 점수
- 양의 상관관계
- Pretraining Influence Score vs. Indegree (왼쪽 그래프)
PageRank는 기본적으로 Indegree와 높은 상관관계를 가짐. 즉, PageRank가 높은 웹페이지는 Indegree도 높은 경우가 많음.
하지만 왼쪽 그래프에서 본 것처럼, Indegree 자체가 Pretraining Influence Score와는 무관하기 때문에, PageRank 기반 크롤링도 LLM 훈련에 적절한 데이터를 선별하는 데 효과적이지 않을 가능성이 높음.
결론은 기존의 LLM을 학습하기 위한 방식의 크롤링으로서 PageRank와 Indree 기반의 크롤링 방식이 "연결성이 높은 문서를 우선 크롤링 하는 방식" → 하지만 이는 LLM 훈련 데이터로서 반드시 유용하지 않음을 논문에서 설명하려고 함
많이 링크된 문서(Indegree↑)가 LLM 훈련에 적합한 데이터(Pretraining Influence Score↑)를 포함할 확률이 낮음 → 기존 크롤링 방식의 비효율성 확인.
3. Methodology
Craw4LLM의 작동 원리 및 기존 크롤러와의 차이점
이 부분에서는 Craw4LLM의 알고리즘과 기존 크롤링 방식과의 차이점을 설명
- Craw4LLM의 개요
- CRAW4LLM은 LLM(대형 언어 모델) 사전 훈련에 적합한 데이터를 우선적으로 크롤링하는 효율적인 웹 크롤링 기법
- 기존의 그래프 연결성(PageRank, Indegree 등) 기반 방식이 아닌, LLM 훈련 기여도(Pretraining Influence Score)를 반영한 크롤링 수행
- Craw4LLM 알고리즘 동작방식
- 초기설정
- 기존 크롤러와 마찬가지로 미리 정해진 시작 URL에서 크롤링을 시작
- Pretraining Influence Score 계산
- 새롭게 발견된 웹페이지(아웃링크)를 평가하기 위해, 각 URL에 대해 "LLM 훈련 기여 점수"를 계산
- 수식:
- 초기설정
$$
s \leftarrow \text{SCORE\_URL}(u;M) = M(\text{FETCHPAGE}(u))
$$
- 수식 설명 :
- FETCHPAGE(u): 해당 URL(u)의 웹페이지 내용을 가져옴
- M(·): LLM 훈련 데이터 필터링 모델이 페이지의 기여도를 평가하여 점수를 부여
3. 우선순위 큐를 이용한 크롤링 결정
- 모든 URL이 평가되면, 우선순위 큐(Priority Queue) 에 삽입
- 점수가 높은 순으로 정렬한 후, 가장 높은 점수를 받은 URL을 다음 크롤링 대상으로 선택
- 이 과정을 반복하여, N개의 문서를 수집할 때까지 크롤링 수행

4. Experimental Methodology
이 부분에서는 CRAW4LLM의 실험 환경과 비교 대상(Baseline) 설정, 평가 방식을 설명하고 있습니다.
- 실험 환경 (CRAW4LLM Experimental Setup)
- 데이터셋
- ClueWeb22-A: 9억 개(900M) 이상의 영어 웹페이지를 포함한 대규모 웹 그래프
- 상업용 검색 엔진의 인덱스에서 추출된 웹페이지 데이터 사용
- 크롤링 시작점(Seed URL)으로 10,000개(10K) URL 무작위 샘플링
- CRAW4LLM 설정:
- 총 크롤링 문서 수 (N): 2천만 개(20M)
- 각 크롤링 반복(iteration)마다 크롤링하는 문서 수 (n): 10,000개(10K)
- 문서 평가 기준:
- DCLM fastText 분류기(Li et al., 2024)를 사용하여 Pretraining Influence Score(LLM 훈련 기여도 점수) 계산
- 점수가 높은 웹페이지를 우선적으로 크롤링
- 비교 실험 (Baseline Methods)
- CRAW4LLM의 성능을 비교하기 위해 기존 크롤링 방식과 비교 실험을 수행
- 기존 그래프 연결성 기반 크롤링
- PageRank, Indegree를 기준으로 크롤링
- 즉, 많은 다른 페이지에서 링크 된 웹페이지를 우선적으로 크롤링
- 상단에 있는 PageRank와 Indegree 그래프를 보면 알 수 있듯이 서로 높은 상관 관게를 가지고 있으므로 대표적인 비교 기준이 될 수 있음.
- 랜덤 크롤링
- URL 점수를 임의로 설정해서 크롤링 실시
- 비교 실험을 위해, 1x 또는 2x 더 많은 문서를 크롤링한 후 필터링 수행
- Crawl-then-Select 방식 적용
- 기존 방식(Random & Indegree)은 먼저 더 많은 문서를 크롤링한 후(1× 또는 2× 크롤링) DCLM fastText 분류기를 적용하여 상위 1×(20M) 문서만 선별
- 이는 기존 데이터 필터링 파이프라인을 모방한 것
- Oracle Selection (이론적 최적 성능)
- 전체 ClueWeb22-A 문서(900M) 중에서 DCLM fastText로 상위 10% 문서만 직접 선택하여 LLM을 훈련
- 이 방법이 가장 이상적인(Oracle) 데이터 선별 방식이며, 100% 성능의 기준(Benchmark)이 됨
- 데이터셋
5. Result
LLM 훈련 및 평가 (LLM Training & Evaluation)
- 411M 파라미터 트랜스포머 모델 사용
- 4x Chinchilla-optimal 토큰 설정 (총 32.9B 토큰 사용)
- 훈련 과정은 DCLM 코드베이스(Li et al., 2024)를 활용하여 수행
평가 방법
- 23개 NLP 태스크에서 성능 평가
- 평가 기준은 DCLM 평가 프로토콜을 따름

5.1 OverallPerformance
이 섹션에서는 Craw4LLM 이 기존 웹 크롤링 방식(Random, Indegree 기반)과 비교하여 얼마나 효율적인지를 평가한 결과를 설명합니다.
1. 실험결과 분석
- Craw4LLM vs 기존 크롤링 방식
- 모든 방법이 동일한 데이터(1x, 20M 문서)로 LLM을 훈련한 결과, Craw4LLM이 기존 크롤러보다 훨씬 우수한 성능을 보임
- 특히 Indegree 기반 크롤링 방식은 가장 낮은 성능을 기록
- Crawl-then-Select 설정에서의 비교
- 기존 크롤러(Random, Indegree 기반 크롤링)는 2× 데이터를 크롤링한 후, 필터링을 통해 1× 데이터를 선택하여 LLM 훈련
- 하지만, 이렇게 더 많은 데이터를 크롤링하고도 CRAW4LLM보다 낮은 성능을 기록
- 이는 사전 훈련 데이터에 적합한 페이지를 초기 크롤링 단계에서 선별하는 것이, 사후 필터링(Post-selection)보다 더 효과적임을 시사
- Craw4LLM vs Oracle Selection
- Oracle Selection : 전체 ClueWeb22 데이터(900M 문서)에서 상위 10% 데이터를 선별 하여 LLM을 훈련한 최적 모델(45x 데이터 사용)
- Craw4LLM은 단 1× 데이터만 크롤링했음에도, Oracle Selection 성능의 95%를 유지.
- Oracle Selection과 거의 유사한 성능을 극도로 적은 크롤링 데이터만으로 달성
% 참고 %
1x, 2x 3x 등등 ... 무슨 말일까?
1×, 2×의 의미
- 1× 데이터 = 100% 기준 데이터 (20M 문서)
- 2× 데이터 = 1×보다 2배 많은 데이터 (40M 문서)
- 4× 데이터 = 1×보다 4배 많은 데이터 (80M 문서)
즉, 2×는 1×보다 두 배 많은 데이터를 크롤링한다는 의미이며, 1× 데이터만 사용할 경우보다 더 많은 웹페이지를 크롤링하여 그중에서 더 좋은 데이터를 선별하는 방식입니다.
5.2 Crawling Efficiency
이 섹션에서는 Craw4LLM의 크롤링 효율성, 문서 커버리지(정확도 및 재현율), 그리고 링크 간 점수 상관관계를 기존 크롤러와 비교 분석합니다.
1. 기존 크롤링과 Craw4LLM의 효율성 비교
- 하기 차트에서 확인할 수 있듯이 기존 크롤러는 4x 데이터를 크롤링해야 하지만 여전히 Craw4LLM보다 성능이 낮음
- 추가적인 분석 결과, Indegree 기반 크롤러는 Craw4LLM의 성능을 맞추기 위해서, 4.8x(96M 양의 문서)를 크롤링 해야함
- 즉, 기존 방식은 수많은 데이터를 크롤링 해야 품질이 보장이 되는 문제 → 데이터 낭비 및 웹사이트 부담 증가
2. 하기 차트 참고 → Craw4LLM은 Indegree 크롤러 대비 21%의 문서만 크롤링 해도 동일한 성능 달성
- 전체 크롤링 한 데이터 양 기준 : Craw4LLM은 기존 Indegree 크롤러의 21% 수준의 데이터만 수집
- Visited(?? 뜻은 잘 모르겠습니다) 문서 기준 크롤러의 48% 수준에서 동일한 성능 달성

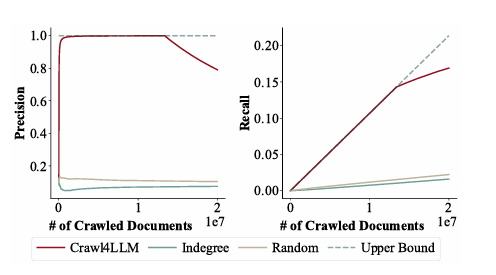
Document Coverage
- Oracle-Selected 데이터와 비교하여 크롤링 데이터의 정확도(Precision)와 재현율(Recall) 분석
- 하기 차트에서 확인이 가능하듯이 Precision(정확도)은 빠르게 1.0에 도달 → CRAW4LLM이 Oracle에서 선정된 데이터를 효과적으로 찾아내고 있음
- Recall(재현율)은 선형적으로 증가하다가 1,300만 개 문서를 크롤링한 이후 성능이 하락
- 이유: ClueWeb22 서브그래프에서 연결성이 낮아 더 이상 유용한 데이터를 찾기 어려워짐
- 즉, CRAW4LLM이 초반에 유용한 데이터를 빠르게 수집하지만, 이후에는 추가적인 데이터 확보가 어렵다는 점을 보여줌
기존 크롤러(Random, Indegree 기반 크롤러)는 Oracle 데이터와의 일치율이 매우 낮음
5.3 Score Correlations Across Links
- 하기 차트에서 확인할 수 있듯이, 현재 문서의 Pretraining Influence Score와 1-hop, 2-hop 아웃링크의 점수 간에 높은 상관관계가 있음
- 즉, 높은 점수를 받은 문서들은 서로 연결되어 있을 가능성이 큼
- 따라서, 기존 문서에서 아웃링크를 추적하여 새로운 고품질 문서를 발견하는 전략이 효과적임을 보여줌

6. Conclusion
이 논문은 CRAW4LLM을 제안하여 LLM 사전 훈련을 위한 웹 크롤링을 더욱 효율적이고 책임감 있게 수행할 수 있도록 개선하는 방법을 제시
1. 주요 기여점
✅ LLM 훈련에 필요한 데이터를 우선적으로 크롤링하는 방식 도입
- 기존 크롤러는 PageRank, Indegree와 같은 그래프 연결성 기반으로 크롤링하지만, 이는 LLM 훈련에 적합하지 않은 데이터를 많이 포함
- CRAW4LLM은 "Pretraining Influence Score"를 기반으로 크롤링 우선순위를 결정하여 LLM 훈련에 적합한 데이터만 효율적으로 수집
✅ 크롤링 효율성 향상 및 불필요한 데이터 크롤링 감소
- 기존 크롤러 대비 최대 4.8배 적은 데이터를 크롤링하면서도 동일한 성능을 유지
- 불필요한 크롤링을 줄여 웹사이트의 부담(Web Host Burden)도 감소
✅ 웹 데이터의 공정 사용(Fair Use) 문제를 고려한 책임 있는 크롤링 방식 제안
- 웹 데이터의 공정 사용과 저작권 문제는 여전히 중요한 과제
- 하지만 CRAW4LLM은 불필요한 크롤링을 줄이고, 최소한의 데이터로 최적의 LLM 훈련 성능을 달성할 수 있도록 설계됨
- 이를 통해 LLM 훈련을 위한 데이터 수집 방식이 보다 윤리적이고 지속 가능(Sustainable)한 방향으로 발전할 수 있도록 기여