https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
1. Abstract
기존 트랜스포머는 자연어처리에서 표준적인 모델로 자리 잡고 있었지만, 컴퓨터 비전 분야에서는 아직 널리 쓰이지 않았음, 기껏해야 CNN을 활용하는 방법에서만 머물렀고, 어텐션 기법을 사용을 하였지만, CNN을 보완하거나 부분적으로 대체하는 식으로만 활용되었음.
하지만 위 논문에서는 CNN 없이도 순수 트랜스포머만으로 이미지 인식이 가능하다는 것을 보여줬는데, 우선 패치 단위로 쪼개서 시퀀스로 만든 후에 트랜스포머의 기존 아키텍처대로 입력하는 방식이 이미지 분류 태스크에서 높은 성능을 보여줬다고 하네요.
또한 대규모 사전학습을 한 후, 이미지넷, CIFAR-100, VTAB 같은 벤치마크에서 적은 자원으로도 최신 CNN보다 좋은 성능을 낸다는 것을 증명했음
🔑 이 문장이 의미하는 논문의 핵심 주장 (Contribution) 정리:
- CNN이 필요 없다 — 순수 Transformer로 이미지 분류 가능.
- 이미지를 패치로 나눠 시퀀스로 입력 — NLP에서 단어를 다루는 것과 같은 방식.
- 대규모 데이터 사전학습 → 소규모 데이터로도 우수한 전이학습(Transfer Learning) 가능.
- SOTA CNN보다 적은 연산 비용으로도 동급 또는 더 좋은 성능.

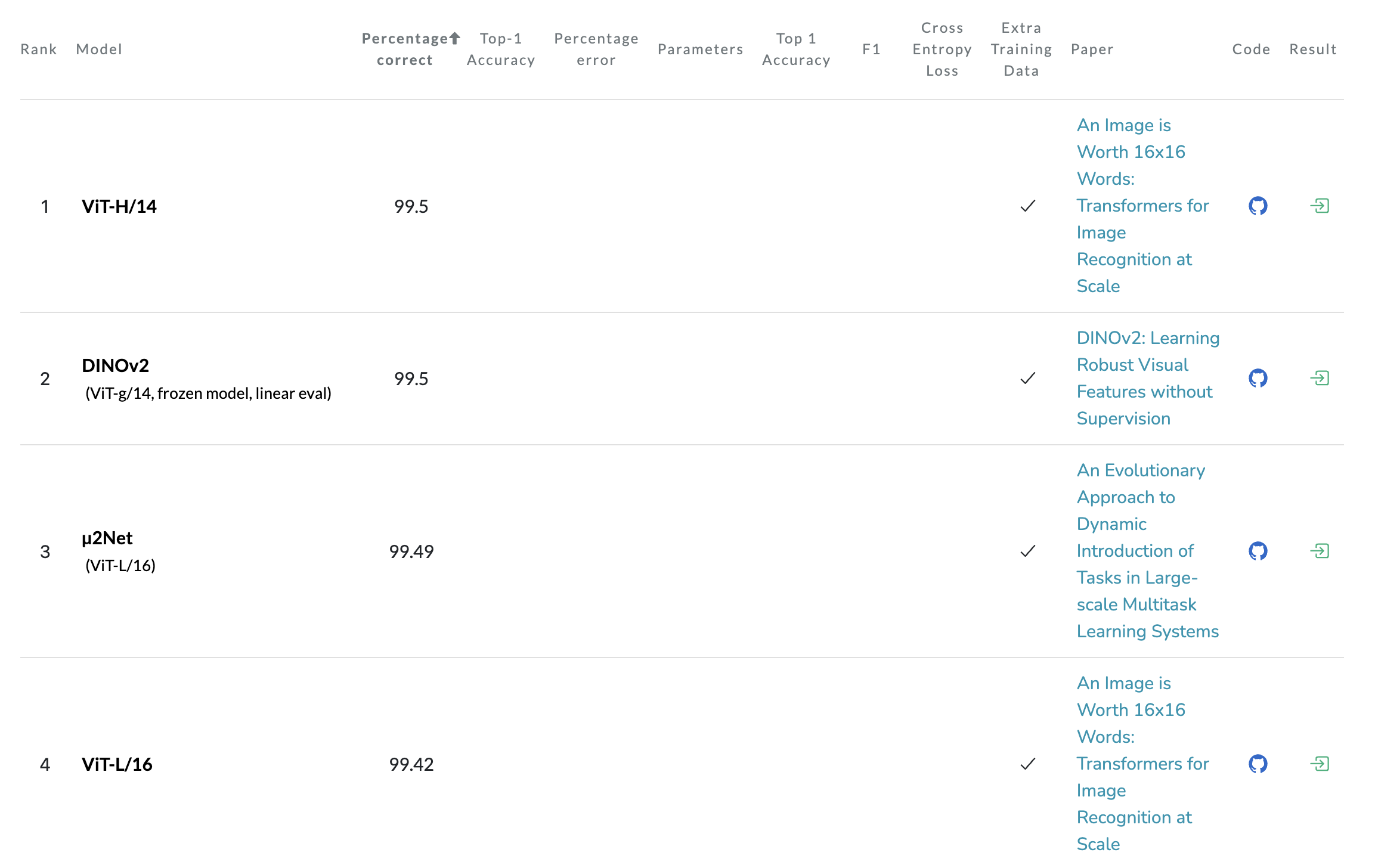
- 상기 리더보드는 ViT가 아직도 CIFAR-10 리더보드에서 우수한 성능을 보인다는 것을 보여주고 있습니다.
2. INTRODUCTION
- 현재 상황
- 트랜스포머 기반의 셀프 어텐션 메커니즘의 모델들은 자연어처리 분야에서 표준 모델로 자리 잡음
- BERT, GPT 같은 모델들이 대규모 사전학습 후 소규모 데이터로 파인튜닝하는 방식으로 큰 성공.
- 1000억 개가 넘는 파라미터 모델들이 등장하며 성능 한계가 보이지 않을 정도로 계속 향상되고 있음.
- 반면, 비전 분야는 CNN에서만 머무르고 있는 상황
- ResNet, EfficientNet 등 고성능 CNN들이 이미지 분야 SOTA를 유지하고 있는 상황
- 최근 많은 연구들이 CNN과 셀프 어텐션을 결합하면서 CNN을 대체하고 있었으나 그것은 완벽하지 못했음.
- 셀프 어텐션의 특수한(?) 패턴(아마도 셀프 어텐션의 병렬 연산을 위한 내적 계산법을 얘기하는 것 같아요)이 하드웨어 가속에 비효율적
- 트랜스포머 기반의 셀프 어텐션 메커니즘의 모델들은 자연어처리 분야에서 표준 모델로 자리 잡음
- 논문 문제의식 제기
- “왜 NLP에서는 트랜스포머로 그렇게 잘 되는데, 비전에서는 아직 CNN이 강세일까?”
- “과연 CNN 없이도 트랜스포머만으로 이미지 인식이 가능할까?” 라며, CNN의 의존에 대한 한계를 지적
- 논문의 접근
- “가장 단순한 방식”으로 트랜스포머를 비전에 적용해보자는 접근으로 시작
- 이미지를 고정된 크기의 패치로 나누고, 이를 시퀀스 형태로 변형(일렬로 나눈다는 것 같아요)
- 각 패치를 선형 임베딩(Linear Embedding) 후 Transformer에 입력.(이 부분이 플랫팅)
- NLP에서 문장을 토큰(token) 단위로 처리하듯, 이미지를 패치(patch) 단위로 시퀀스로 처리.
- 완전한 트랜스포머 모델로서 이미지 분류 작업을 시행
- “가장 단순한 방식”으로 트랜스포머를 비전에 적용해보자는 접근으로 시작
이 이후에, ViT가 데이터의 양에 따라 얼만큼의 성능을 보이는지에 대해 논문에서 정리하였는데요,
중간 규모 데이터셋 (예: ImageNet, 약 140만 장) 으로 강한 정규화 없이 ViT를 학습시키면, 비슷한 크기의 ResNet 모델보다 몇 퍼센트 정도 성능이 낮다. 라는 결론이 나왔습니다.
왜 그런지에 대해서 연구진들은 고민하면서 정리하였는데, 그것은 CNN만의 국소성이라는 이유 때문이었습니다.
트랜스포머에 비교해서 CNN에서 가지고 있던 중요한 특성:
- Translation equivariance (위치가 바뀌어도 인식 가능): CNN은 이미지를 옮겨도 같은 물체로 인식하는 성질이 자동으로 포함됨.
- Locality (국소성): CNN은 근처 픽셀끼리 관계를 쉽게 파악하는 구조.
트랜스포머는 전역적으로 이미지를 보고 CNN은 근처 픽셀끼리의 특징 그러니까, 지역적으로 보는 특성이 있기에 충분하게 큰 데이터가 없으면 트랜스포머는 유효하지 않았다는 결론을 냈음.
그렇기에 대규모 데이터를 통해 학습을 시도하게 됨.
- 14M~300M 장 수준의 매우 대규모 데이터셋으로 학습
- 대규모 학습이 CNN의 inductive bias (구조적 강점)를 이긴다.
- 즉, 데이터가 충분히 크면, CNN의 강점을 굳이 모방하지 않아도 트랜스포머가 더 잘 배울 수 있다
그렇게 큰 데이터로 사전 학습(pre-training) 후, 소규모 데이터셋으로 전이학습(transfer learning)하면 아주 좋은 성과를 얻음.
구체적인 수치
| 벤치마크 데이터셋 | ViT 최고 성능 (Accuracy) |
| ImageNet | 88.55% (SOTA 근접/초과) |
| ImageNet-ReaL | 90.72% (보다 깨끗한 라벨 사용 버전) |
| CIFAR-100 | 94.55% (소형 이미지 분류, 매우 높은 성과) |
| VTAB (19 tasks) | 77.63% (19개 다양한 비전 작업 평균 정확도) |
이 수치는 기존 CNN 기반 SOTA 모델과 비슷하거나 더 뛰어난 성능이었고, 특히, 300M장 규모의 JFT-300M 같은 초대형 데이터셋으로 학습했을 때 가능했던 결과임.
3. RELATED WORK
ViT의 등장과 관련 연구, 왜 순수 트랜스포머가 주목받는가?
최근 자연어 처리(NLP) 분야에서 트랜스포머는 사실상 표준 모델로 자리 잡았습니다. 이제는 “Transformer 없이 NLP를 논할 수 있을까?” 싶을 정도죠. 그런데 이 강력한 트랜스포머를 이미지 인식에도 똑같이 쓸 수 있을까라는 논제부터 시작했습니다.
이 질문에 대한 답을 본격적으로 던진 것이 바로 Vision Transformer (ViT)입니다. 하지만 ViT가 등장하기까지, 그리고 ViT와 비슷하거나 관련된 연구들이 어떤 것이 있는지를 알 필요가 있습니다. 이번 글에서는 ViT 논문의 관련 연구(RELATED WORK) 부분을 바탕으로 트랜스포머의 비전 분야 적용에 대해 차근차근 살펴보겠습니다.
1. 트랜스포머, 자연어 처리(NLP)의 절대 강자
Transformer는 Vaswani et al. (2017)의 논문 *“Attention is All You Need”*에서 처음 제안되었고, 이후 NLP의 핵심 기술로 자리 잡았습니다.
특히, BERT (Devlin et al., 2019), GPT (Radford et al., 2018; 2019; Brown et al., 2020) 같은 대규모 모델들이 거대한 데이터로 사전학습 한 후, 다양한 작업에 파인튜닝 하여 탁월한 성능을 보여주었음.
이렇게 대용량 사전학습 + 소규모 파인튜닝의 조합이 NLP의 공식처럼 자리 잡음
2. 그렇다면 왜 비전에서는 트랜스포머를 바로 적용하기 어려웠는지?
랭귀지와는 다르게 이미지는 모든 픽셀 단위를 서로 어텐션 메커니즘에 적용해야 했는데, 이 경우 계산량이 O(n²)로 폭증하기에 비효율적인 문제가 가장 컸음.
그래서 많은 연구들이 트랜스포머의 좋은 성질은 살리면서, 이미지에 맞는 방식을 고민하게 되었다고 논문에서 얘기합니다.
3. 기존 시도: 트랜스포머를 비전에 적용하기 위한 다양한 변형들
(1) 국소적(Local) Self-Attention
- Parmar et al. (2018): 모든 픽셀이 아니라 근처 픽셀들만 주목하게 해서 계산량을 줄임.
- 이후 Hu et al. (2019), Ramachandran et al. (2019), Zhao et al. (2020) 등도 국소적인 self-attention을 통해 CNN을 대체하는 시도.
(2) Sparse Transformer
- Child et al. (2019): 일부 중요한 부분만 선택적으로 주목하게 하는 방식.
- 이렇게 하면 글로벌 어텐션(global attention)과 비슷한 효과를 내면서도 계산량을 획기적으로 절감.
(3) 블록과 축 방향 Attention
- Weissenborn et al. (2019): 블록 단위로 주목.
- Ho et al. (2019), Wang et al. (2020a): 가로 또는 세로 방향으로만 주목하는 Axial Attention 사용.
이런 방식도 계산량 줄이기 위한 아이디어.
그렇지만 이 모든 방식은 계산량은 어느정도는 줄일 수 있지만, 모델 구조 자체가 복잡해지는 가장 큰 문제가 발생하였음.
4. ViT와 유사한 선행 연구: Cordonnier et al. (2020)
비슷한 시도로 Cordonnier et al. (2020)이 있습니다. 이들은 이미지를 2x2 픽셀 단위 패치로 나눈 후, 그 위에 full self-attention을 적용했어요.
하지만 한계가 존재
- 작은 해상도의 이미지에만 가능.
- 큰 이미지 처리는 어려움.
반면 ViT는 더 큰 패치 (예: 16x16)를 사용하고, 중간~대규모 해상도의 이미지도 처리할 수 있음
그리고 거대한 데이터로 사전학습해 CNN을 넘는 성능을 보여준다는 점에서 차별화 됨.
5. CNN + Self-Attention을 결합한 연구들
한편, 트랜스포머를 CNN과 결합하려는 시도들도 많았음.
- Bello et al. (2019): CNN feature map에 self-attention 추가.
- Carion et al. (2020): DETR 모델로 object detection에 attention 결합.
- Hu et al. (2018), Wang et al. (2018), Wu et al. (2020): 다양한 분야에서 CNN+Attention 결합.
- Chen et al. (2020c), Lu et al. (2019), Li et al. (2019): 이미지와 텍스트 같이 다루는 멀티모달 모델.
즉, “CNN은 필요하고, Attention은 보조”라는 접근이 대부분이었음.
6. iGPT (image GPT): Transformer로 이미지 생성
트랜스포머만으로 이미지를 다루려는 시도 중 가장 유명한 시도는 iGPT (Chen et al., 2020a)입니다.
- 이미지를 픽셀 단위로 시퀀스로 보고 Transformer 적용.
- 하지만 해상도, 색상 축소 필요.
- 비지도 학습(unsupervised) 방식.
- 성과: ImageNet 72% 정확도 (아직 CNN보다 낮음).
7. 데이터 크기와 성능의 관계: 대규모 학습의 중요성
최근 들어 단순히 모델 구조만으로 한계를 넘기는 어렵다는 것이 알려지고 있습니다.
- Mahajan et al. (2018), Xie et al. (2020): ImageNet보다 훨씬 큰 데이터로 CNN 훈련.
- Sun et al. (2017): 데이터가 커질수록 CNN 성능도 올라감.
- Kolesnikov et al. (2020), Djolonga et al. (2020): ImageNet-21k, JFT-300M 같은 초대형 데이터로 실험.
즉, 모델보다는 데이터 크기가 게임 체인저라는 흐름이 나오고 있다고 논문에서는 설명하네요.
8. ViT의 차별점
| 기존 접근 방식 | Vision Transformer (ViT) |
| CNN + Self-Attention 혼합 | 순수 Transformer로 구성 |
| 복잡한 로컬/스패스 Attention 설계 필요 | 일반 Transformer 구조 유지 |
| 소규모 데이터셋 중심 (ImageNet 등) | JFT-300M, ImageNet-21k 등 초대형 데이터 활용 |
| 작은 패치 (2x2) 중심 | 중간 크기 패치 (16x16) 사용, 대규모 이미지도 대응 |
4. METHOD
Vision Transformer (ViT)의 모델 설계: 왜 단순한 구조가 강력한가?
1. Transformer를 최대한 그대로 가져오다
ViT가 가지는 가장 큰 특징 중 하나는 바로 “가능한 한 원본 Transformer를 그대로 사용한다”는 점입니다.
“In model design we follow the original Transformer (Vaswani et al., 2017) as closely as possible.”
- 즉, NLP에서 사용된 Transformer의 구조를 거의 수정 없이 이미지 인식에 적용했습니다.
- “이미지에 맞게 이것저것 복잡하게 바꾸자”가 아니라,
- “그냥 트랜스포머를 그대로 써도 되는지 보자”는 접근입니다.
2. 왜 이렇게 단순하게 했을까?
✅ (1) 확장 가능한 구조 (Scalable Architecture)
- NLP 분야에서 이미 매우 대규모 Transformer 모델들이 성공적으로 사용되고 있습니다.
- 예를 들어, GPT-3 같은 모델은 1000억 개가 넘는 파라미터를 다루면서도 안정적으로 작동하죠.
- ViT는 이처럼 이미 검증된 대규모 Transformer 구조를 이미지에 바로 적용할 수 있다는 의미입니다.
✅ (2) 효율적인 구현 (Efficient Implementations)
Transformer는 이미 딥러닝 프레임워크(TensorFlow, PyTorch 등)에서 고도로 최적화된 라이브러리로 구현되어 있습니다.
따라서 새로운 모델을 설계하거나 구현하는 추가 비용이 적다는 장점이 있습니다.
✅ (3) 유연성과 범용성 (Flexibility and Generality)
NLP에서 쓰던 Transformer 아키텍처를 이미지에 쓰면서, 이후 멀티모달 (텍스트 + 이미지) 작업까지 쉽게 확장 가능.

5. VISION TRANSFORMER (VIT)
앞서 Transformer 구조를 그대로 가져온다는 Vision Transformer (ViT)의 설계 철학을 알아보았습니다.
그렇다면 실제로 이미지를 어떻게 트랜스포머가 이해할 수 있는 형태로 바꿀까요?
이번 글에서는 ViT가 이미지를 시퀀스로 변환하고 Transformer로 처리하는 방식을 자세히 설명해보겠습니다
1. 이미지를 패치단위로 자르기.(Patch)
트랜스포머는 원래 단어(토큰) 시퀀스를 처리하는 모델입니다. 따라서 이미지를 Transformer에 넣으려면 이미지를 쪼개서 시퀀스처럼 만들어야 합니다.
- ViT에서는 이미지를 고정된 크기의 패치 (Patch)로 나눕니다.
\(x \in \mathbb{R}^{H \times W \times C}\)
- 여기서 \(H, W\) 는 이미지의 높이와 너비, \(C\) 는 채널 수 (예: RGB면 3).
- 패치 하나의 크기:
\((P, P)\)
- 이렇게 나누면 총 패치 수 \(N\) :
\(N = \frac{H \times W}{P^2}\)
- 각 패치를 펴서(Flatten) 하나의 벡터로 만들고, 이 벡터들을 모아서 시퀀스를 구성합니다:
\(x_p \in \mathbb{R}^{N \times (P^2 \cdot C)}\)
2. 패치를 임베딩(Embedding) 벡터로 변환하기
$$
z_0 = [x_{\text{class}}; x_1^p E; x_2^p E; \dots; x_N^p E] + E_{\text{pos}}
$$
- \( E \): 선형 임베딩 행렬, \( E \in \mathbb{R}^{(P^2 \cdot C) \times D} \)
- \( E_{\text{pos}} \): 위치 인코딩 (Position Embedding), \( E_{\text{pos}} \in \mathbb{R}^{(N+1) \times D} \)
- \( x_{\text{class}} \): BERT의 [CLS] 토큰처럼 분류용 추가 토큰
각 패치를 Transformer가 처리할 수 있도록 고정된 차원의 벡터로 변환합니다.
이를 선형 변환으로 수행합니다.
3. 포지셔널 임베딩을 추가(아마 포지셔널 인코딩과 같이 위치 값을 부여하는 것 같아요)
트랜스포머는 순서가 없는 시퀀스를 처리하므로 패치 순서를 알 수 있는 위치 정보를 추가합니다.
\(E_{\text{pos}} \in \mathbb{R}^{(N+1) \times D}\)
- ViT에서는 1차원(1D) 학습 가능한 위치 임베딩을 사용합니다.
- 복잡한 2D 위치 인코딩 없이도 충분한 성능을 보였기 때문입니다.
4. Transformer Encoder로 시퀀스 처리
이제 임베딩된 패치 시퀀스를 표준 Transformer Encoder에 넣어 처리합니다.
트랜스포머의 핵심 구성:
- Layer Normalization (LN)
- Multi-Head Self-Attention (MSA)
- Residual Connection
- Layer Normalization (LN)
- MLP (2층 feed-forward network, GELU activation 사용)
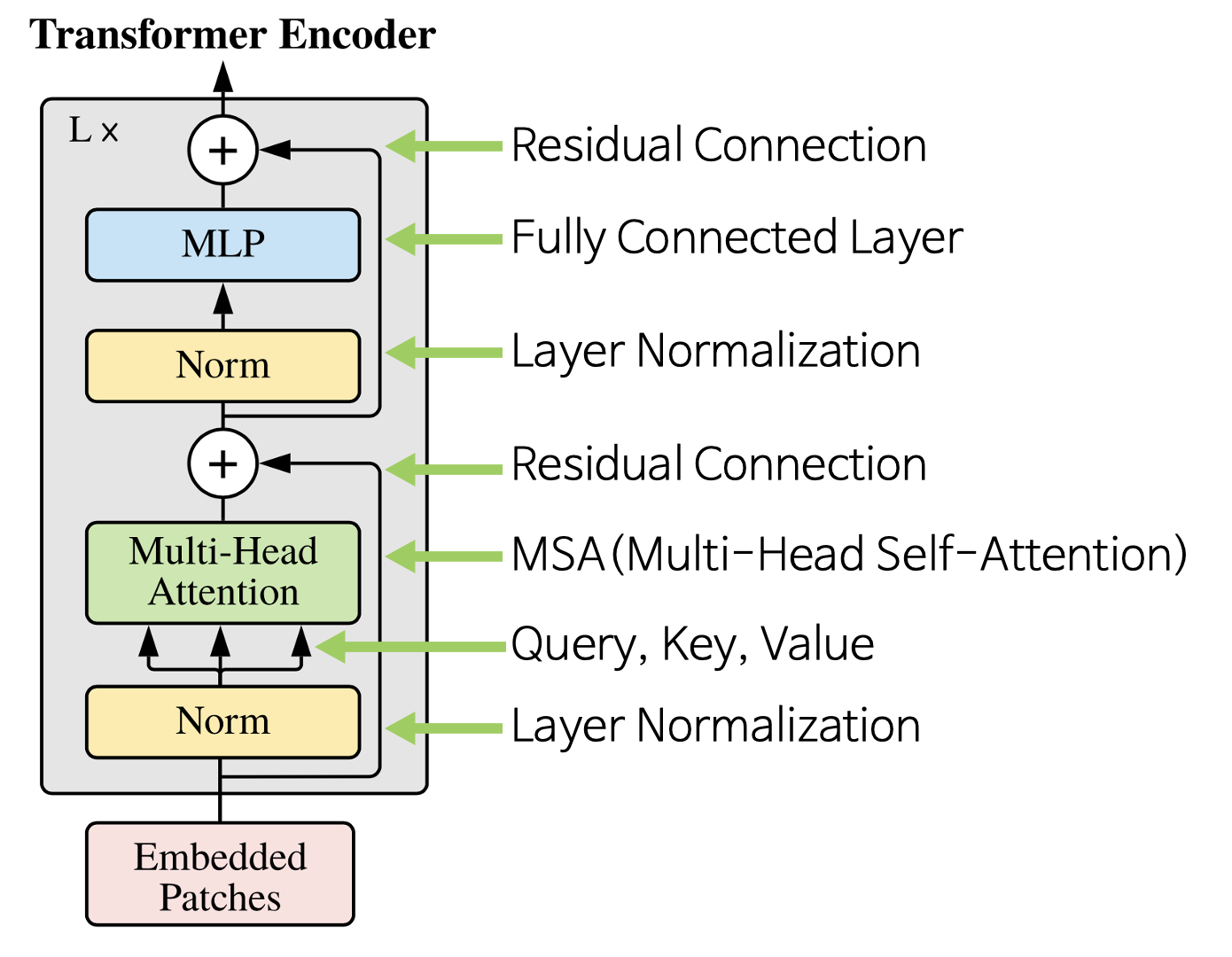
특이한 점은, 기존 바닐라 Transformer와 달리 ViT에서는 Layer Normalization의 위치가 바뀌어 있다는 점입니다.
원래 Transformer에서는 포지셔널 인코딩을 추가한 후 Multi-Head Attention과 Feed-Forward Network를 거치고, 그 출력에 대해 정규화(Layer Normalization)를 수행했습니다 (Post-LN 방식).
하지만 Vision Transformer는 정규화를 블록의 맨 앞에 먼저 적용하는 Pre-LN 방식을 채택했습니다.
이는 이미지 데이터를 시퀀스로 다루면서 발생할 수 있는 내부 공변량 변화 (Internal Covariate Shift) 를 완화하고, 학습 안정성(stability)을 높이기 위한 의도로 해석할 수 있습니다.
따라서 Attention과 MLP가 입력받기 전 항상 안정된 분포를 갖도록 보장하는 아키텍처 설계로 볼 수 있습니다.
수식으로 보는 아키텍처 연산 과정
$$
z_{\ell}^{\prime} = \text{MSA}(\text{LN}(z_{\ell-1})) + z_{\ell-1}, \quad \ell = 1, \dots, L
$$
$$
z_\ell = \text{MLP}(\text{LN}(z_{\ell}^{\prime})) + z_{\ell}^{\prime}, \quad \ell = 1, \dots, L
$$
- \( L \): Transformer 인코더의 총 레이어 수
- \( z_\ell \): 인코더의 각 레이어 출력
5. 최종 이미지 표현 (Representation)
$$
y = \text{LN}(z_0^L)
$$
- \( y \): 최종 이미지 표현 (이미지 전체 정보를 요약한 벡터)
- 이 벡터를 분류기에 넣어 이미지 분류 수행

5-2. FINE-TUNING AND HIGHER RESOLUTION
Vision Transformer (ViT)의 파인튜닝(Fine-tuning)과 고해상도 처리 방법
1. 파인튜닝(Fine-tuning) 방식
ViT는 기본적으로 사전학습된 분류기(prediction head)가 포함되어 있습니다.
하지만 다운스트림 작업에 맞추기 위해 기존 분류기를 제거하고, 새로운 분류기를 붙입니다.
- 기존 분류기 제거
- 새로운 Feed-forward layer (크기 \(D \times K)\) 추가)
- 여기서 (\(D\): 트랜스포머의 출력차원, \(K\): 다운스트림 작업의 클래스 수)
- 이 새로운 분류기는 가중치를 0으로 초기화(zero-initialized)하여 처음부터 새로 학습.
2. 고해상도 이미지로 파인튜닝하기
ViT는 사전학습 시 사용한 이미지보다 더 높은 해상도의 이미지로 파인튜닝 하는 것이 종종 성능 향상에 도움이 됩니다.
(참고: Touvron et al., 2019; Kolesnikov et al., 2020)
왜 고해상도가 필요한가?
• 더 많은 디테일을 포함한 이미지를 학습하면서 더 정교한 특징을 잡을 수 있기 때문
3. 고해상도 이미지를 처리하는 방식
3.1 패치 크기(Patch size)는 그대로
패치 크기 \((P \times P)\) 는 그대로 유지.
따라서 해상도가 높아질수록 패치 수\((N)\) 가 증가 → 시퀀스 길이가 길어짐.
3.2 위치 임베딩(Position Embedding)의 재조정
문제:
- 사전학습 시의 위치 임베딩(position embedding)은 고정된 패치 수\((N)\) 에 맞춰져 있음.
- 고해상도 이미지 → 패치 수 증가 → 기존 위치 임베딩 그대로 사용 불가.
해결:
- 기존 위치 임베딩을 2D로 해석해서 새로운 시퀀스 길이에 맞게 보간 (2D interpolation).
\(\text{New Position Embedding} = \text{Interpolate}(\text{Pre-trained Position Embedding}, \text{New Patch Grid})\)
즉, 원본 이미지에서의 위치에 따라 위치 임베딩을 재조정해서 고해상도 이미지에서도 자연스럽게 positional 정보가 반영되도록 합니다.
4. 유일하게 2D 구조를 반영하는 부분
ViT는 기본적으로 2D 이미지의 공간 정보를 명시적으로 사용하지 않는 모델입니다.
하지만 예외적으로 다음 두 부분에서만 이미지의 2D 구조(Spatial Bias)가 반영 된다고 설명합니다.
| 단계 | 설명 |
| 패치 추출 (Patch Extraction) | 이미지를 \(P \times P\) 크기의 패치로 분할 |
| 위치 임베딩 재조정 (Position Embedding Interpolation) | 고해상도 이미지에 맞게 위치 임베딩을 2D 보간으로 확장 |
즉, 이 두 지점만이 ViT가 이미지의 2D 특성을 수동으로 반영하는 유일한 순간입니다.
결론
ViT는 학습 시에는 단순 시퀀스 모델처럼 작동하지만, 고해상도 파인튜닝과 위치 보간을 통해 이미지의 2D 특성을 최소한으로 반영합니다.
이 과정을 통해 더 나은 일반화 성능과 고해상도에 대한 유연성을 갖추게 되는 것이죠.
6. EXPERIMENTS
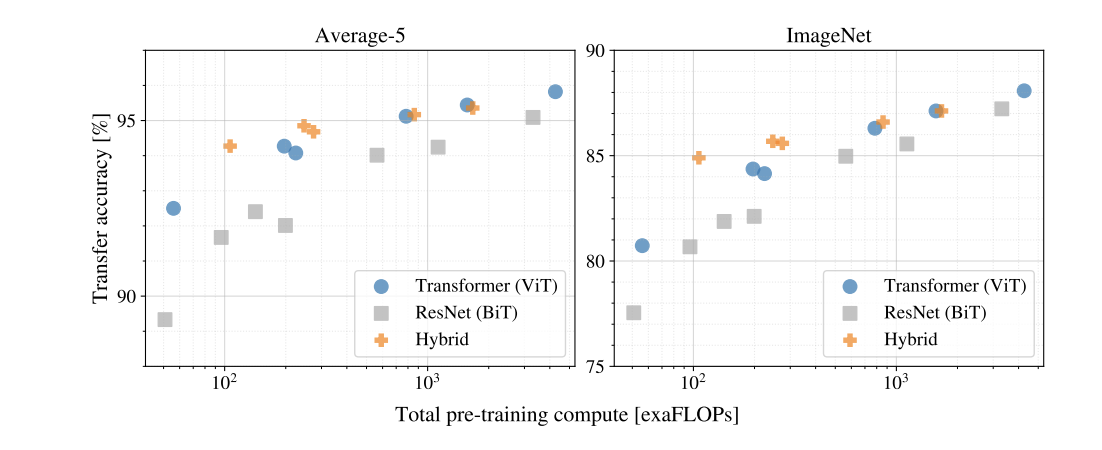
Vision Transformer (ViT)는 ResNet, Hybrid 모델과 함께 다양한 실험을 통해 평가되었습니다. 이 실험의 핵심은 ViT의 표현 학습 능력, 데이터 요구량, 연산 효율성, 자기지도학습 가능성을 확인하는 것이었습니다.
- 표현 학습 성능 (Representation Learning)
- ViT는 대규모 데이터셋(JFT-300M 등)에서 ResNet보다 뛰어난 성능을 보임.
- 소규모 데이터셋에서는 여전히 CNN 계열이 유리.
- 2. 데이터 의존성 (Data Dependency)
- ViT는 충분한 데이터가 주어질 때 강력한 성능을 발휘.
- 데이터가 적을 때는 전통적 CNN이 더 강함.
- 연산 비용 (Computational Cost)
- ViT는 더 적은 사전학습 비용으로 대부분의 벤치마크에서 SOTA 성과.
- CNN 대비 효율적.
- 자기지도학습 가능성 (Self-supervised Learning)
- 초기 실험에서 자기지도학습으로도 의미 있는 표현 학습 가능성 확인.
- 향후 확장성 기대.
사용 데이터셋 (Datasets)
| 데이터셋 | 클래스 수 | 이미지 수 | 설명 |
| ImageNet (ILSVRC-2012) | 1,000 | 1.3M | 가장 널리 사용되는 이미지 분류 데이터셋 |
| ImageNet-21k | 21,000 | 14M | ImageNet 확장판, 더 많은 클래스와 이미지 포함 |
| JFT-300M | 18,000 | 303M | 초대형 고해상도 데이터셋 (Google 사내 데이터) |
Vision Transformer (ViT)는 대규모 데이터로 사전학습 후 다양한 벤치마크로 전이되어 평가되었으며, ResNet 및 Hybrid 모델과 비교 시 효율성과 성능에서 모두 강점을 보였습니다. 모델 크기, 시퀀스 길이, 패치 크기, 학습 및 평가 방식 모두 일관되게 통제된 환경에서 수행되었습니다.
성능결과표


7. PRE-TRAINING DATA REQUIREMENTS
Vision Transformer (ViT)의 사전학습 데이터 요구 (Pre-training Data Requirements)
가장 중요하다고 판단합니다.
ViT가 ResNet과 다른 점 중 하나는 이미지에 특화된 inductive bias (국소성, 평행이동 불변성 등)가 적다는 것입니다.
따라서 모델이 스스로 복잡한 패턴을 학습하기 위해서는 훨씬 많은 데이터가 필요할 수 있습니다.
이번 섹션에서는 ViT가 데이터 크기에 따라 얼마나 성능이 영향을 받는지를 두 가지 실험을 통해 확인했습니다.
1. 실험 1: 데이터 크기에 따른 성능 변화 (Dataset Size Scaling)
- 세 가지 다른 크기의 데이터셋으로 ViT 모델 사전학습:
- ImageNet (1.3M 이미지)
- ImageNet-21k (14M 이미지)
- JFT-300M (303M 이미지)
- 작은 데이터셋에 대해 성능 향상을 위해 정규화 (weight decay, dropout, label smoothing) 조정.
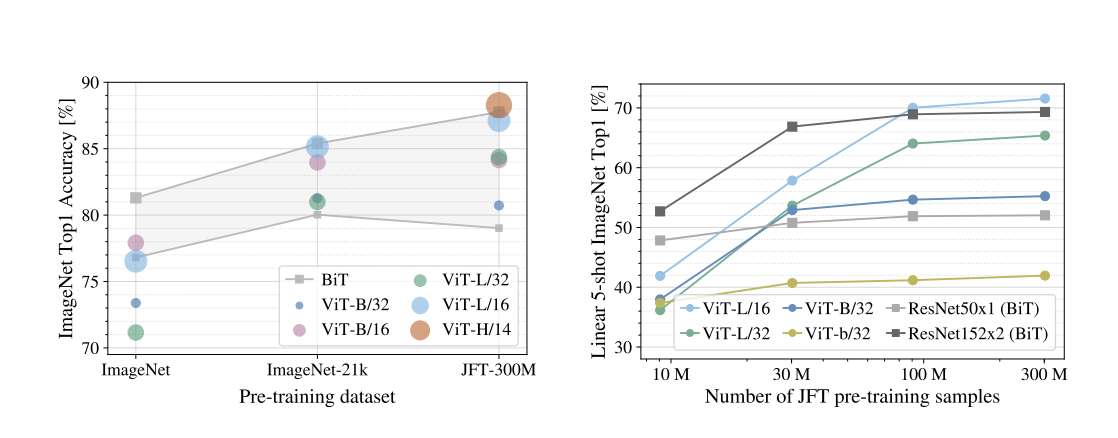
- ImageNet (소규모 데이터):
- ViT-Large는 ViT-Base보다 오히려 성능이 낮음.
- 대규모 모델이 오버핏(overfitting) 문제 발생.
- ImageNet-21k (중간 규모):
- ViT-Base와 ViT-Large 성능 비슷.
- JFT-300M (초대형 데이터):
- ViT-Large가 ViT-Base를 명확히 능가.
- 대규모 모델의 진가 발휘.
“충분히 큰 데이터가 주어질 때, 큰 모델이 더 잘 작동한다.”는 결론을 얻음
2. 실험 2: JFT 데이터 서브셋에 따른 성능 (Subset Scaling)
- JFT-300M의 일부만 사용해서 실험:
- 9M, 30M, 90M, 전체 (303M) 이미지로 모델 훈련.
- 정규화 조정 없이 동일한 하이퍼파라미터 사용 (모델 고유 성능 평가 목적).
- Few-shot linear accuracy로 평가 (전체 fine-tuning 대신).
결과 :
- 작은 서브셋 (예: 9M)에서는 ViT가 ResNet보다 훨씬 성능 낮음 (과적합).
- 데이터가 커질수록 ViT 성능 급격히 향상:
- 90M 이상의 데이터에서는 ResNet 성능 초월.
- ViT는 대량 데이터 없이는 ResNet만큼 일반화 어려움.
- ResNet (BiT)은 작은 데이터에서도 견고하지만, 데이터가 커져도 상대적 향상폭이 적음.
“ViT는 작은 데이터에서는 약하지만, 큰 데이터에서는 훨씬 강력하다.”을 얻음
8. Inspecting Vision Transformer
Vision Transformer (ViT) 내부 작동 방식 분석 (Inspecting Vision Transformer)
Vision Transformer (ViT)는 이미지를 패치로 분해하고, Transformer로 처리하지만, 그 내부에서 어떻게 이미지 정보를 해석하고 통합하는지는 흥미로운 질문입니다.
이 섹션에서는 ViT의 내부 표현과 Self-Attention 메커니즘을 시각적으로 분석한 결과를 소개합니다.
1. 입력 패치의 임베딩 (Input Patch Embedding)
ViT의 첫 번째 레이어는 이미지 패치(Flattened Patches)를 선형 임베딩(Linear Embedding)을 통해 고정된 차원의 벡터로 변환합니다.
이 임베딩 필터들의 주성분 분석(Principal Components) 결과:
- 각 패치 내의 미세한 구조(fine structure)를 표현하는 기저 함수(Basis Function)와 유사한 패턴 발견.
- 즉, ViT는 처음부터 패치 내부의 복잡한 정보를 요약하는 효과적인 표현을 학습.
2. 위치 임베딩 (Position Embedding)의 역할
임베딩된 패치 벡터에 학습된 위치 임베딩(Position Embedding)이 추가됩니다.
- 위치 임베딩 분석 결과:
- 서로 가까운 패치들은 유사한 위치 임베딩을 가짐.
- 같은 행(row)이나 같은 열(column)에 있는 패치들은 비슷한 임베딩을 가지는 경향.
- 큰 격자(grid)에서는 때때로 사인 함수와 유사한 주기적 구조(sinusoidal structure)도 나타남.
결론:
ViT는 2D 이미지의 공간적 관계를 학습된 위치 임베딩을 통해 자연스럽게 표현하기 때문에, 수작업으로 설계된 2D-aware 임베딩이 필요 없는 이유를 설명.
3. Self-Attention의 정보 통합 (Global & Local Attention)
Transformer의 핵심인 Self-Attention 메커니즘은 이미지 전체의 정보를 통합할 수 있는 능력을 제공합니다.
ViT가 실제로 이 능력을 어떻게 활용하는지를 분석했습니다.
“Attention Distance” 개념:
- Attention을 통해 통합되는 평균 거리.
- CNN의 수용장 (Receptive Field)와 유사한 개념.

발견된 패턴 (Figure 7, 오른쪽 분석 결과):
1. 낮은 층 (Low Layers):
- 일부 Attention Head는 이미 이미지 전체를 참조 (Global Attention).
- 다른 Head는 매우 국소적인 주의 (Local Attention) → 초기 CNN 계층과 유사한 역할.
2. 깊은 층 (Deeper Layers):
- Attention Distance가 증가 → 더 넓은 범위의 정보를 통합.
- 점점 더 복합적이고 전역적인 특징을 잡음.
4. ViT가 주목하는 부분 (Input Attention)
Figure 6 분석 결과:
- ViT는 이미지 내에서 분류와 관련된 의미적(semantically relevant) 부분에 집중.
- 모델이 이미지의 중요한 부분을 정확히 인식하고 있음.

5. CNN 기반 Hybrid 모델과의 비교
Hybrid 모델 (ResNet + Transformer)에서는 국소적 Attention (Localized Attention)이 ViT보다 덜 나타남. 이는 이미 CNN이 로컬 특징 추출을 했기 때문.
8-1. SELF-SUPERVISION
Vision Transformer (ViT)와 자기지도학습(Self-supervised Learning) 가능성
ViT의 자기지도학습 (Masked Patch Prediction)
ViT에서도 BERT의 마스킹 기반 자기지도학습 (Masked Language Modeling)에서 영감을 받아
Masked Patch Prediction 방식을 시도했습니다.
- 이미지 일부 패치를 가리고(masked), 나머지 패치로부터 가려진 패치를 예측하도록 학습.
- 텍스트의 단어 예측처럼, 이미지의 결손된 부분을 복원하도록 학습.
| 모델 | 학습방식 | ImageNet 성능 (Top-1 Accuracy) |
| ViT-B/16 | 자기지도학습 (Masked Patch Prediction) | 79.9% |
| ViT-B/16 | 지도학습 (Supervised Pre-training) | 약 83.9% |
| ViT-B/16 | 무사전학습 (Training from scratch) | 약 77.9% |
실험결과
- 자기지도학습만으로 79.9% 성능 → 사전학습 없이 직접 학습 대비 약 2% 향상.
- 그러나 지도학습 대비 약 4% 성능 차이 존재.
- 아직은 지도학습이 성능 면에서 더 우수하지만, 자기지도 방식의 가능성 확인.
향후 연구 방향 (Future Directions)
현재는 Masked Patch Prediction만 시도했지만,
더 강력한 자기지도학습 방식인 대조학습(Contrastive Learning) 방식은 아직 탐색되지 않았습니다.
향후 연구 대상으로 제안된 대조학습 기법:
- SimCLR (Chen et al., 2020b)
- MoCo (He et al., 2020)
- Momentum Contrast (Bachman et al., 2019)
- CPC (Henaff et al., 2020)
'멀티모달_프로젝트' 카테고리의 다른 글
| [멀티모달 프로젝트 후기] 모델 개발 (4) | 2025.06.05 |
|---|