https://arxiv.org/abs/2005.14165
Language Models are Few-Shot Learners
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fi
arxiv.org
1. Abstract
1. 최근 NLP 연구의 흐름
방대한 텍스트를 통해서 사전학습을 한 후에, 특정 태스크에 맞는 형식의 미세조정 방식이 다양한 자연어처리 작업과 벤치마크 큰 성과를 내고 있는 상황임.
예를 들어, 위키백과로 공부한 다음 감정 분석 작업만 따로 연습하는 방식
2. 기존 방식의 문제점
모델의 구조는 일반적인 작업에도 쓸 수 있도록 설계되어 있지만, 여전히 각 과제마다 수천에서 수만 개 라벨링 된 학습 데이터가 필요함, 이 방식의 단점은 과제가 달라질 때마다 새로운 데이터셋을 만들어야 하는 문제 예를 들어서 영어 문장을 한국어로 번역하고 싶으면 그에 맞는 수만개의 쌍 데이터 예시를 준비해서 학습시켜야 함
3. 인간과의 차이점
그렇지만 인간은 언어 모델과는 다르게 간단한 예시와 설명만으로도 새로운 과제에 대한 과제를 잘 수행할 수 있는 특징이 있음 그렇기에 언어모델 자체로는 이러한 하이브리드한 능력이 부족하다는게 가장 큰 논지
4. 위 논문의 핵심 아이디어
위 논문에서는 언어 모델의 크기를 거대하게 키운다면, few-shot, zero-shot 등이 눈에 띄게 좋아진다는걸 보여준다는 것을 보여준다고 함.
(그래서 OPENAI는 GPT-3를 1750억개의 파라미터로 만들어버림;;)
5. 실험 방식
GPT-3는 어떠한 과제도 별도의 학습 없이, 오직 텍스트로 된 지시와 예시만을 통해 작업을 수행할 수 있도록 함.
아래 내용은 미세조정 없이, 파인튜닝 없이 단지 텍스트로 "이런 식으로 해" 라고 하고 몇 개 예시만 주는 방식으로 테스트 함.
예)
## Example
Q: 영어 문장 "I am happy"를 한국어로 번역하시오.
A: 나는 행복하다.
# Test
Q: I am sad
A: ?
6. 높은 성능
GPT-3는 번역, 질문응답, 빈칸 채우기 등 다양한 자연어 과제에서 좋은 성능을 보였음. 또, 단어 조합 맞추기, 새로 만든 단어 쓰기, 간단한 계산 등 새로운 과제도 꽤 잘 해냄
번역, 문장 완성, 질문에 답하기 같은 전통적인 NLP 과제뿐 아니라, 즉석에서 새로운 단어를 이해하고 쓰기, 계산하기, 단어 섞기 풀기 같은 복잡한 작업도 잘하게 됨
결론
이 논문은 “AI가 단 몇 개의 예시만 보고도 사람처럼 유연하게 언어 작업을 해낼 수 있을까?”라는 질문에 대해, GPT-3라는 초거대 모델이 상당한 가능성을 보여주었다고 말함
1. Introduction
최근 자연어처리에서는 사전학습과 미세조정을 결합한 방법이 주류가 되어 큰 성과를 내고 있음. 그렇지만 이 방식은 여전히 작업마다 많은 양의 라벨링 된 데이터를 필요로 했고, 위 논문에서는 "그 필요성을 줄이거나 없앨 수는 없을까?" 라는 문제의식에서 부터 출발했다고 하네요.
논문에서는 인간처럼 간단한 지시나 몇 가지 예시만으로도 다양한 작업을 수행할 수 있는 모델이 필요하다는 것이 핵심 주장입니다.
“최근 몇 년간 NLP 시스템에서는 점점 더 유연하고 특정 작업에 얽매이지 않는 방식으로 사전 학습된 언어 표현을 사용하는 흐름이 나타났습니다.”
- 초기에는 단어 임베딩(word vector) 같은 단일 층 표현을 이용했음(예: Word2Vec, GloVe).
- 이후에는 RNN 기반 모델로 문맥 정보까지 담을 수 있게 되었고, 최근에는 Transformer 기반 모델이 등장해서, 사전학습만으로도 다양한 작업에 활용 가능하게 됐음
“파인튜닝은 독해, 질의응답, 의미판별 등 다양한 어려운 NLP 작업에서 상당한 성과를 보여주고 있으며, 여전히 새로운 아키텍처나 알고리즘 덕분에 계속 발전 중.”
- BERT, RoBERTa, T5 같은 모델들이 이 방식에 해당됨
- 하지만 성능이 좋음에도 불구하고, 작업마다 수많은 파인튜닝을 위한 많은 데이터가 필요하다는 한계가 있음.
그렇지만 모델이 커질수록 우연한 패턴(?) 이라는 현상에 의해서 따라 배워버리는 경향이 생김
- 그 결과로 테스트 데이터셋에서만 맞춰져있고, 실제 제로 샷을 통해 던졌을 때는 잘 적응하지 못하는 문제가 발생해버림
이러한 단점을 딛고 GPT-3에서는 Few-shot, One-shot, Zero-shot등의 다양한 학습 태스크를 통해 능동적으로 학습하는 모델을 지향하며 만들게됨
- 약 1750억개의 파라미터를 보유하고 있음
- 어떤 작업이든 파인튜닝 없이 진행
- 오직 텍스트의 입력만으로 다양한 작업에 도전
인간의 학습능력을 모방하기 위함이 가장 큰데 인간은 간단한 지시문이나 1~2개 예시만 있어도 금방 이해하고 수행 가능한 인지능력을 가지고 있음. 가령 예를 들어 몇가지의 댓글 데이터들의 분위기를 읽어 보기만해도 긍정인지 부정인지를 판단할 수 있기에 언어 모델도 그에 걸맞는 능동적인 판단을 할 수 있도록 훈련하는 방법이 In-context Learning(즉, Meta-Learning이라고도 합니다)이라고 함
In-context Learning?

Meta-Learning(메타 학습) 이라고도 하는데
- “학습을 위한 학습”
- AI가 단순히 데이터를 외우는 게 아니라, 학습의 방법 자체를 학습하는 것을 말함
- 즉, 새로운 작업이 주어졌을 때 빠르게 적응할 수 있는 능력을 기르는 방식( Zero-Shot )
In-Context Learning(컨텍스트 내 학습) 이란?
- 모델이 주어진 문맥만 보고 작업을 수행하는 방식
- 즉, 모델의 파라미터를 업데이트하지 않고, 입력된 텍스트만으로 학습 효과처럼 작동하게 만드는 방식
상기 이미지에서도 설명된 내용이지만 가령 예를 들자면
Q: 2 + 2 = ?
A: 4
Q: 3 + 5 = ?
A:
- GPT-3는 이런 형식이 반복되는 것을 보고 “아! 이건 덧셈 문제구나”라고 문맥 속에서 학습(in-context)하고,
- 그다음 문제(3+5)에 대해서 A: 8이라고 추론하게 됨.
- 이 과정에서 모델의 파라미터는 전혀 업데이트되지 않는 것이 포인트
직관적인 예시로 한 번 더 이해하기
기존 문법 교정 작업을 위한 사전작업에서는
- 문법 교정 작업을 하려면, 교정된 문장 10,000개로 fine-tuning 필요
GPT-3 (In-context learning):
예시 1:
틀린 문장: She go to school every day.
고친 문장: She goes to school every day.
예시 2:
틀린 문장: He don't like apples.
고친 문장: He doesn't like apples.
문제:
틀린 문장: They is happy.
고친 문장:
- GPT-3는 위 예시들을 보고 “아! 문법 교정이구나”라고 이해하고
- They are happy. 라고 적절히 이어서 답함.
인간과 비교되는 AI 적응력의 한계
사람은 대화 중에 갑자기 계산하거나, 문법을 고치거나, 주제를 바꿔도 자연스럽게 대처하는데. 그렇지만 대부분의 언오 모델은 단일 작업에 특화되어 있고, 작업을 넘나드는 유연성이 부족함.
결국에는 언어 모델도 인간처럼 이런 작업 간 유연성과 일반성을 가져야 진짜 쓸모가 있다는 의견
해결책으로 제안되는 “메타 러닝(meta-learning)”
- Meta-learning이란, 모델이 단순한 지식이 아니라 ‘학습하는 방법 자체를 학습’하는 것
- 여기서 중요한 개념이 바로 in-context learning:
- 훈련 시점에는 다양한 패턴과 작업을 배워두고, 추론(inference) 시점에는 텍스트 안의 작업 지시 또는 예시만 보고도 적응해서 문제를 푸는 방식
- 모델 파라미터를 바꾸지 않고, 입력 텍스트로만 적응. (** 제일 중요)

“큰 모델일수록 문맥 정보를 더 잘 활용한다.”
- 이 Figure는 아주 간단한 과제를 예로 들어줌:예: “h#e@l*l^o!” → “hello” → 문자열에서 랜덤 기호들을 제거하는 작업
- 실험 방식은 두 가지:
- 자연어로 설명만 주는 경우
- “기호를 제거하고 단어를 정리하세요.”
- 예시만 주는 경우
- 입력과 정답 쌍을 몇 개 제시
- 자연어로 설명만 주는 경우
- 결과는?
- 즉, 더 큰 모델일수록 문맥 속 예시를 더 잘 일반화하고 이해함
- 모델이 커질수록 성능이 가파르게 향상됨
여기서 중요한 점
1. 태스크에 대한 자연어 설명은 모델 성능을 향상시킨다
- 모델에 단순히 예시만 제공하는 것보다, 이 작업은 무엇을 하는 건지”를 자연어로 명시적으로 설명해주는 것이 성능 향상에 도움이 된다는 발견
2. 모델의 문맥 윈도우에 더 많은 예제를 놓을수록 성능이 향상 (K에 비례하여 정확도 증가)
- 모델이 컨텍스트 창(Context Window)에 들어가는 예시 수 K가 많을수록, few-shot 학습 성능도 비례해서 상승하는 경향을 보인다는 말
3. 큰 모델일수록 in-context 정보를 잘 활용
- 파라미터 수가 많을수록(=모델이 클수록), 주어진 예시나 자연어 설명 등 문맥 속 정보를 더 잘 해석하고 활용할 수 있다는 점
제일 중요한건 이 데이터들이 학습하는 과정에서 파라미터의 업데이트는 일절 일어나지 않는다는 사실을 집중해야 함.
진행 배경과 한계점
인간과 비교되는 AI 적응력의 한계
사람은 대화 중에 갑자기 계산하거나, 문법을 고치거나, 주제를 바꿔도 자연스럽게 대처함. 그렇지만 대부분의 언어 모델은 단일 작업에 특화되어 있고, 작업을 넘나드는 유연성이 부족한 현실.
결국 언어모델도 인간처럼 이런 작업 간 유연성과 일반성을 가져야 진짜 쓸모가 있다는 의견.
해결책으로 제안되는 “메타 러닝(meta-learning)”
- Meta-learning이란, 모델이 단순한 지식이 아니라 ‘학습하는 방법 자체를 학습’하는 것
- 여기서 중요한 개념이 바로 in-context learning:
- 훈련 시점에는 다양한 패턴과 작업을 배워두고,
- 추론(inference) 시점에는 텍스트 안의 작업 지시 또는 예시만 보고도 적응해서 문제를 푸는 방식
- 모델 파라미터를 바꾸지 않고, 입력 텍스트로만 적응함.
한계
초기 성과는 있지만, 여전히 fine-tuning보다 성능이 떨어진다.”
- RWC(2019)는 Natural Questions에서 단 4% 성능
- CoQA에서 55점 F1 → 당시 최고 성능보다 35점 낮음
in-context learning은 가능성은 있지만, 실용성 확보는 아직 미흡하다는 한계를 명확히 짚고 있음
모델 규모의 증가
“언어모델의 규모가 커질수록 NLP 성능도 계속 향상되었다.”
- 모델 크기의 발전 흐름:
- 1억 → 3억 → 15억 → 80억 → 110억 → 170억 파라미터 등
- GPT-3는 이 흐름의 연장선, 모델 크기의 극단적 확장을 시도한 것
규모 확장이 in-context learning 능력도 같이 향상시킬 수 있을까? → 바로 이 논문이 검증하고자 하는 질문
연구 목표와 방법
- GPT-3는 사전학습만 수행하고, 그 이후에는 파인튜닝 없이 작업을 수행함
- 실험 환경은 세 가지:
- Few-shot: 문맥에 10~100개 예시 제공
- One-shot: 예시 1개 제공
- Zero-shot: 예시 없이 자연어 지시문만 제공
주요 실험 결과
- GPT-3는 대부분의 NLP 태스크에서 zero, one, few-shot 모두 준수한 성능
- 특히 few-shot에서는 일부 fine-tuned 모델보다 더 높은 성능도 보임
| 작업 | Zero-Shot | One-Shot | Few-Shot |
| CoQA (질의응답) | 81.5 F1 | 84.0 F1 | 85.0 F1 |
| TriviaQA (지식 QA) | 64.3% | 68.0% | 71.2% (SOTA 수준) |
GPT-3의 특징과 능력
- 빠른 적응력: 정의 한 번만 보고 새로운 단어를 문장에 사용하는 능력
- 즉석 추론: 간단한 수학 계산, 단어 순서 바꾸기 등도 수행 가능
- 텍스트 생성 능력: 사람과 구별하기 어려운 뉴스 기사 생성 가능
한계점
그러나 ANLI나 QuAC처럼 복잡한 언어 이해를 요하는 일부 태스크에서는 성능이 미흡했다고 하네요 모든 작업에서 GPT-3가 잘했다고 볼순 없습니다.
데이터 오염(data contamination) 문제
Common Crawl처럼 공개 웹 기반 데이터셋에는 평가 데이터와 유사하거나 동일한 내용이 포함될 위험이 있는데, 이러한 오염은 모델 성능을 부정확하게 부풀릴 수 있다. 이에 따라 연구진은 자체 도구로 데이터 오염을 측정하고, 문제가 있는 데이터셋의 결과는 보고하지 않거나 *표시로 명시하였음
결론
GPT-3의 편향성과 공정성 문제, 그리고 사회적 영향에 대해서도 논의하며 책임 있는 AI 개발을 위한 고려사항을 제시한다. 전체적으로 이 논문은 사전학습 기반의 대규모 언어 모델이 파인튜닝 없이도 인간처럼 문맥에서 학습하고 적응할 수 있는 가능성을 보여주는 중요한 사례
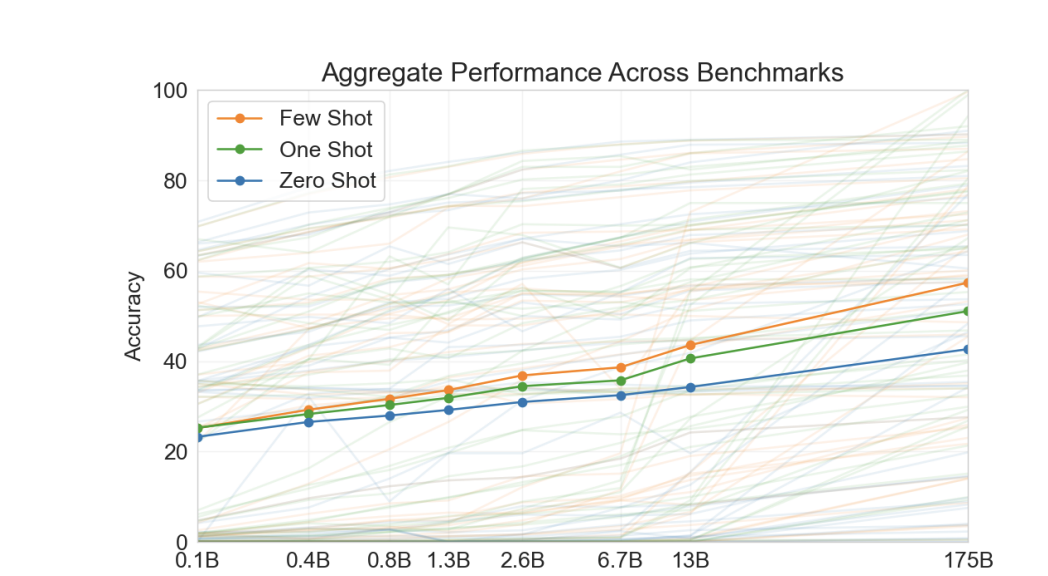
3. Approach
기본적인 사전학습 접근법(모델, 데이터, 훈련 기법)은 대부분 GPT-2와 비슷함. 모델 크기를 키우고, 데이터 양과 다양성을 증가시키며 훈련 기간을 늘렸음. In-context 학습법도 GPT-2와 비슷하게 진행함. 하지만 본 논문에서는 GPT-3을 평가하는 방법을 다음과 같이 네 가지로 세분화하여 정의하였음.
- 파인튜닝(fine-tuning) 방식 : 보편적인 NLP 학습 방법, 특정 작업에 맞는 감독학습 데이터셋으로 다시 학습시켜 조정하는 방법 수천에서 수십만 개의 라벨된 예시가 필요하며, 성능은 높지만 매번 새로운 데이터셋이 필요하고, 과적합이나 일반화 실패 가능성, 인간 성능과의 불공정한 비교 등의 문제가 발생할 수 있다. GPT-3는 이 논문에서 파인튜닝을 수행하지 않았으나, 파인튜닝이 불가능한 것은 아니며 미래 연구 방향으로 제시된다.
- Few-Shot Learning : 이 설정에서는 모델에 10~100개의 예시를 문맥에 포함시켜 문제를 푸는 방식 여기서 중요한 점은, 모델의 파라미터는 고정된 채, 예시들은 오직 문맥을 통해 태스크가 주어짐 예를 들어, 영어 문장과 그에 대응하는 프랑스어 번역 쌍을 K개 제시하고, 마지막 문장의 번역은 모델이 직접 생성하도록 한다. 이 방식은 task-specific 데이터 의존도를 낮추고, 좁은 분포의 fine-tuning 데이터에 의한 편향 문제도 줄일 수 있다. 하지만 현재까지는 fine-tuned 모델보다는 성능이 낮고, 여전히 최소한의 예시가 필요하다는 한계가 있다.
- one-shot learning : few-shot과 거의 같지만, 예시를 단 하나만 제공하며, 여기에 더해 자연어로 된 작업 설명(instruction)도 함께 제공된다. 이 방식은 특히 사람이 작업을 전달받는 방식과 유사한 점에서 유의미하다. 예를 들어, 크라우드소싱 플랫폼에서 작업자를 고용할 때는 하나의 예시와 간단한 지시문만으로 작업을 안내하는 경우가 흔하다. 예시 없이 작업을 설명하는 것은 오히려 전달이 더 어려울 수 있다.
- zero-shot Learning : 이 방식에서는 예시 없이 자연어 설명만 제공되며, 모델이 그 설명만으로 작업의 구조와 목적을 이해하고 수행해야 한다. 이 설정은 편의성과 일반화 가능성은 높지만, 예시 없이 작업 형식을 완전히 이해해야 하므로 가장 어렵다. 예컨대, “200m 달리기 세계 기록을 표로 만들어주세요”라는 요청은, 표의 형식이나 포함 항목이 명확하지 않기 때문에 사람에게도 해석이 어려울 수 있다.
GPT-3 논문은 이러한 세 가지 in-context 방식들을 서로 경쟁하는 대안이 아니라, 작업별 특성과 효율성의 균형을 고려한 다양한 문제 설정으로 간주한다. 특히 few-shot 방식은 여러 과제에서 기존 fine-tuned 모델과 비교해도 큰 성능 차이가 없는 결과를 보이며, fine-tuning을 대체할 수 있는 가능성을 제시한다. 하지만 근본적으로는, one-shot이나 zero-shot과 같은 방식이 인간과의 공정한 비교 지점에 더 가깝기 때문에, 향후 연구의 핵심 목표로 삼을 가치가 있다.

쉽게 정리하는 GPT-3의 태스크 수행 방식
| 구분 | 설명 | 데이터 필요성 | 파라미터 업데이트 | 모델 사용 시기 |
| Fine-tuning | 사전학습 모델을 특정 작업에 맞게 추가 학습시키는 방식 | 수천~수만 개 라벨 데이터 | 있음 | 훈련(training) 단계에서 사용 |
| Few-shot | 문맥(context)에 여러 개의 예시(K = 10~100)를 제공하고, 그 문맥만으로 작업 수행 | 일부 필요 | 없음 | 추론(inference) 단계에서 사용 |
| One-shot | 예시 1개 + 자연어 설명(instruction) 제공 | 매우 적게 필요 | 없음 | 추론 단계에서 사용 |
| Zero-shot | 예시 없이 자연어만 던짐 | 없음 | 없음 | 추론 단계에서 사용 |
3.1 Model and Architectures
모델의 크기를 점진적으로 확장하며 총 8가지 버전의 모델을 학습 및 테스트했으며, 가장 작은 모델은 1억 2천 5백만 개의 파라미터를, 가장 큰 모델은 총 1750억 개의 파라미터를 가짐. 이 GPT-3 모델은 96개의 레이어, 12,288 차원의 히든 레이어, 96개의 attention head로 구성되어 있음. 모든 모델은 3000억 개의 토큰을 기반으로 학습되었음.(하기 테이블을 보며 크기에 따른 파라미터와 레이어들을 비교하면 됨)
모든 모델은 2048 토큰의 고정된 context window를 사용하며, 학습 시에는 계산 자원을 효율적으로 활용하기 위해 모델의 깊이(depth)와 너비(width)를 기준으로 GPU 간 병렬 처리(parallelization)를 수행함. 레이어 수(nlayers), 각 레이어의 크기(dmodel), attention head의 차원(dhead) 등은 모두 계산 효율성과 GPU 간 부하 균형(load balancing)을 고려해 설정되었으며, 이러한 세부 아키텍처는 성능을 크게 저해하지 않는 선에서 최적화되었다는 기존 연구 결과를 반영해 설계됨.

여기서 눈여겨 봐야 할 부분은 모델이 커짐에 따라서 학습률을 점점 낮춘다는 것이다.
왜 모델이 커질수록 학습률을 낮추는가?
1. 큰 모델은 더 민감하다 (Gradient Sensitivity)
- 파라미터가 많아질수록, 학습 중 작은 변화도 큰 영향을 미침
- 따라서 학습률이 너무 높으면 불안정한 학습(발산)으로 이어질 수 있음
- 안정적인 학습을 위해 작은 step으로 천천히 학습시키는 것이 안전함
2. 표현력이 높은 모델일수록 더 섬세한 조정이 필요
- 대규모 모델은 이미 많은 개념과 패턴을 내포하고 있음
- 이를 fine-tuning하듯 세밀하게 조정해야 하기 때문에 너무 큰 업데이트는 위험
- 따라서 학습률을 줄여서 ‘과도한 학습’을 방지
3. Loss landscape가 복잡해짐
- 모델 크기가 커질수록, loss 곡선이 더 복잡하고, local minima도 더 많아짐
- 높은 학습률로 학습하면 불안정한 경로를 지나며 좋은 최소점을 놓칠 가능성이 있음
- 낮은 학습률은 더 안정적으로 loss를 줄이면서 최적점을 찾아갈 수 있게 해줌
3.2 Training Dataset
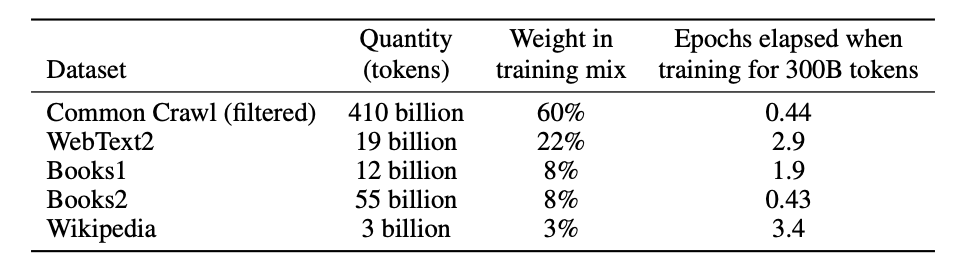
사전학습에 있어, Common Crawl을 중심으로 방대한 웹 기반 데이터를 사용했는데, 품질 향상을 위해 다음과 같은 방법으로 텍스트 클리닝을 진행함.
1. 고품질 코퍼스 유사도 기반 필터링:
Common Crawl 데이터를 다양한 고품질 기준 데이터셋과 비교하여 유사도가 높은 문서만 선택
2. fuzzy deduplication(중복 제거):
데이터셋 내 또는 서로 다른 데이터셋 간에 중복된 문서를 제거하여 과적합을 방지하고, 검증셋의 신뢰도를 확보
3. 고품질 데이터셋 추가:
Common Crawl의 한계를 보완하고 다양성을 높이기 위해, 다음과 같은 선정된 고품질 데이터셋을 추가로 혼합하여 사용
- WebText (확장 버전)
- Books1, Books2 (인터넷 기반 도서 코퍼스)
- English Wikipedia
4. Result
GPT-3 논문은 총 8개의 모델(125M ~ 175B 파라미터)뿐 아니라, 이보다 더 작은 6개의 초소형 모델(최소 10만 파라미터)까지 포함하여 모델 크기와 성능 간의 관계를 분석했다.
실험에서 측정한 성능 지표는 검증 데이터에 대한 cross-entropy loss이며, 이는 모델의 예측 정확도를 반영하는 핵심적인 척도다.
실험 결과, 모델 크기와 학습에 사용된 연산량(compute)을 증가시킬수록 성능은 매우 일정한 power-law 곡선 형태로 향상되었으며, 이 추세는 기존 연구(KMH+20)에서 제안된 경향을 그대로 따랐다.
여기서 Power-law 곡선형태?
모델 크기나 연산량을 늘릴 때 성능이 일정한 법칙에 따라 향상된다는 것을 의미
\(y = ax^k\)
여기서 식을 따라 정리하자면
- \(y : \) 결과 값 (예: 성능, loss등)
- \(x: \) 입력 값 (예: 모델크기, 연산량 등)
- \(a, k:\) 상수 (\(k\)는 기울기 또는 비율 조절자)
즉, 모델이 커질수록, 더 많이 훈련할수록, 예시를 더 많이 제공할수록 → 성능이 일정한 곡선 형태로 향상된다는 의미
GPT-3처럼 파라미터 수가 100배 이상 증가한 경우에도 이 곡선에서 크게 벗어나지 않고 성능이 예측 가능한 방식으로 증가함을 확인했다. 이는 모델이 커질수록 성능 향상이 계속 이어진다는 강력한 근거로 작용한다.
일각에서는 이러한 성능 향상이 단지 학습 데이터에 포함된 잡음(spurious details)을 과하게 모델링한 결과일 수 있다는 우려도 있다. 그러나 논문은 이후 다양한 자연어 처리 과제에서 cross-entropy loss의 감소가 실제 태스크 성능 향상으로 이어진다는 점을 수차례 실험을 통해 보여준다.
이후 3장에서 GPT-3와 다른 7개 모델을 다음 9개 범주에 따라 다양한 태스크에 대해 평가한다:
- 전통적인 언어모델링 및 클로즈 테스트
- “클로즈드 북(closed-book)” 질문응답
- 기계번역 (특히 one-shot/few-shot)
- Winograd Schema 문제
- 상식 추론
- 독해 과제 (Reading Comprehension)
- SuperGLUE 벤치마크
- 자연어 추론 (NLI)
- in-context learning 능력을 평가하기 위한 창의적 과제들
모든 태스크는 zero-shot, one-shot, few-shot 세 가지 설정에서 평가되며, 이를 통해 모델의 적응력과 일반화 능력을 체계적으로 분석한다.

3.1.2 LAMBADA
모델 크기를 키우는 것이 여전히 효과적인가?라는 물음에 대한 대표적인 테스트
LAMBADA는 텍스트 내 장거리 의존성(long-range dependencies)을 평가하는 대표적인 자연어 처리(NLP) 벤치마크. 이 과제는 단순한 문장 예측이 아닌, 여러 문단에 걸친 문맥을 모두 고려해야만 마지막 단어를 정확히 예측할 수 있는 문장들로 구성되어 있음. 따라서 단기 기억보다는 긴 문맥 이해력이 요구되며, 기존 언어 모델에게는 매우 까다로운 과제였다.
LAMBADA (문장 완성하기/ 언어의 장기 의존성을 모델링하는 태스크)

최근까지도 연구자들은 모델을 아무리 키워도 LAMBADA에서의 성능 향상은 점점 둔화되고 있다고 지적해는데. 예를 들어, 과거 연구(BHT+20)에 따르면 모델 크기를 2배 키워도 정확도가 겨우 1.5% 오르는 등의 효율 저하 현상이 관찰되었다고 함.

이는 GPT-3가 평가받는 데 있어 중요한 배경 맥락이 된다. 이 모델은 무려 1750억 개의 파라미터를 가진 초대형 모델로, 기존 모델보다 훨씬 규모가 크다. 따라서 LAMBADA 같은 장거리 문맥 이해가 필요한 과제에서 과연 의미 있는 성능 향상을 보일 수 있을지가 중요한 검증 포인트가 된다.
이후 본문에서는 GPT-3가 LAMBADA에서 few-shot, one-shot, zero-shot 각각 어떤 성능을 보였는지가 구체적으로 평가된다. 그리고 결과적으로 GPT-3는 이전보다 확연한 성능 향상을 달성함으로써, 단순한 파라미터 증가가 여전히 의미 있는 성능 개선으로 이어질 수 있음을 실험적으로 입증한다. (상기 테이블 결과 내용을 기반으로)

상기 차트를 보면 알 수 있지만, 제로-샷, 원-샷, 퓨-샷을 통해 GPT-3가 얼만큼 정확도를 달성했는지 확인할 수 있다.
정리
- GPT-3는 LAMBADA zero-shot 설정에서 76% 정확도 달성 → 기존 SOTA보다 +8%p
- Few-shot 설정에서는 빈칸 채우기 방식 도입 → 86.4% 정확도 → 기존 SOTA보다 +18%p
- 작은 모델은 성능 저하, 큰 모델일수록 성능 급상승 → 스케일 효과 명확
HellaSwag
- 목표: 이야기나 지시문의 가장 적절한 결말을 선택하는 과제
- 특징: 인간에겐 쉽지만, 언어모델에는 어렵게 설계됨 (인간 정확도 95.6%)
✅ GPT-3 성능:
One-shot: 78.1%
Few-shot: 79.3%
기존 fine-tuned 1.5B 모델(75.4%)보다 우수, 그러나 SOTA (ALUM, 85.6%)보다는 낮음
StoryCloze
- 목표: 다섯 문장짜리 이야기에서 올바른 마지막 문장을 고르는 과제
- Zero-shot: 83.2%
- Few-shot (K=70): 87.7%
- 기존 **BERT 기반 SOTA (91.8%)**보다 4.1% 낮지만, 기존 zero-shot 결과 대비 약 10% 향상
Closed-Book Question Answering
일반적인 QA 시스템은 검색 시스템(IR)을 사용하여 관련 문서를 찾고, 그 정보를 바탕으로 답변함 → Open-book QA(RAG 같기도해요)
Closed-book QA는 외부 문서 없이 모델의 내부 지식만으로 직접 답변해야 함
- GPT-3는 파인튜닝 없이, 오직 zero-, one-, few-shot 방식으로만 질문에 답함 → 매우 제약이 큰 실험 조건

역량 결과
| 데이터셋 | Zero-shot | One-shot | Few-shot | Fine-tuned 비교 모델 | GPT-3 성능 해설 |
| TriviaQA | 64.3% | 68.0% | 71.2% | T5-11B: 57.0% / RAG: ~68% | Fine-tuned 모델보다 최대 +14.2% 높음 |
| WebQuestions | 14.4% | 25.3% | 41.5% | T5-11B: 37.4% / T5-11B+SSM: 44.7% | Few-shot 기준으로 최신 SOTA와 근접 |
| Natural Qs | 14.6% | 23.0% | 29.9% | T5-11B+SSM: 36.6% | 상대적으로 낮은 성능 → 세부 지식 기반 질문 때문 |
Translation
훈련 데이터 구성
- 전체 텍스트 중 93%는 영어, 7%는 다국어, 비영어 텍스트도 자연스럽게 혼합되어 학습됨
GPT-3의 번역 학습 특징
- 별도의 번역용 구조나 목적 함수 없이 통합된 언어모델로 학습
- 기존의 unsupervised MT처럼 back-translation 사용 안 함
성능 결과 (하기 Table)
- Zero-shot: 최신 unsupervised 번역 모델보다 다소 낮은 성능
- One-shot / Few-shot:
- 단 1개~64개 예시만 제공해도 성능 크게 향상
- 일부 언어쌍에서 기존 unsupervised NMT 모델 능가

Winograd-Style Tasks
문맥 기반 대명사 해석 능력평가
예시:
“The trophy doesn’t fit into the suitcase because it is too small.” → 여기서 “it”이 무엇을 가리키는지 모델이 문맥을 통해 추론해야 함
단순 통계로 해결할 수 없으며, 논리적/상식적 추론이 필요함
- GPT-3는 Winograd 스타일 태스크에서 few-shot 설정으로 실험됨
- 정확한 수치는 본문에 제한적이나, 주요 평가 데이터셋에서 상당한 개선된 성능을 보였다고 명시됨
- 특히, 모델이 커질수록 대명사 해석 정확도 향상이 뚜렷하게 나타남

Common Sense Reasoning
GPT-3가 일상적인 상황에서의 논리적 추론이나 상식적 판단을 얼마나 잘 수행할 수 있는지를 테스트 단순 언어 통계가 아닌, 배경 지식과 인과 관계 이해가 필요한 문제
- few-shot 설정에서 기존 모델보다 전반적으로 향상된 정확도 달성
- 특히 PIQA, SIQA 등에서 기존 fine-tuned 모델들과 경쟁 가능하거나 초과
- 성능은 모델 크기에 따라 꾸준히 증가
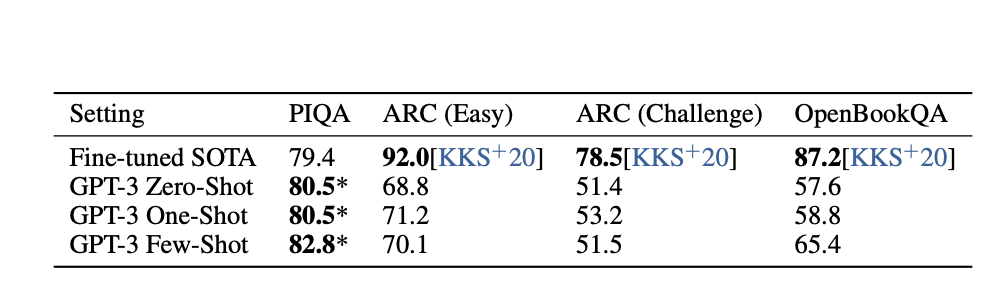
Reading Comprehesion
독해능력임
GPT-3가 긴 지문을 읽고, 그에 따라 정확한 정보 추출, 이해, 응답을 할 수 있는지를 측정
질의응답(QA) 형태의 과제 중심
- RACE: 중고등 수준 영어 독해 문제
- QuAC: 대화 기반 질의응답
- CoQA: 다중 문장 이해 + 연속적 질문응답
CoQA:
- Zero-shot: 81.5 F1
- One-shot: 84.0 F1
- Few-shot: 85.0 F1 → SOTA 수준
RACE / QuAC:
- GPT-3가 고전적인 독해 문제에서는 다소 성능이 낮음
- 특히 RACE는 복잡한 문제 구조로 인해 few-shot에서도 어려움
GPT-3의 인-컨텍스트 러닝의 결과가 상대적으로 약했던 실험 결과
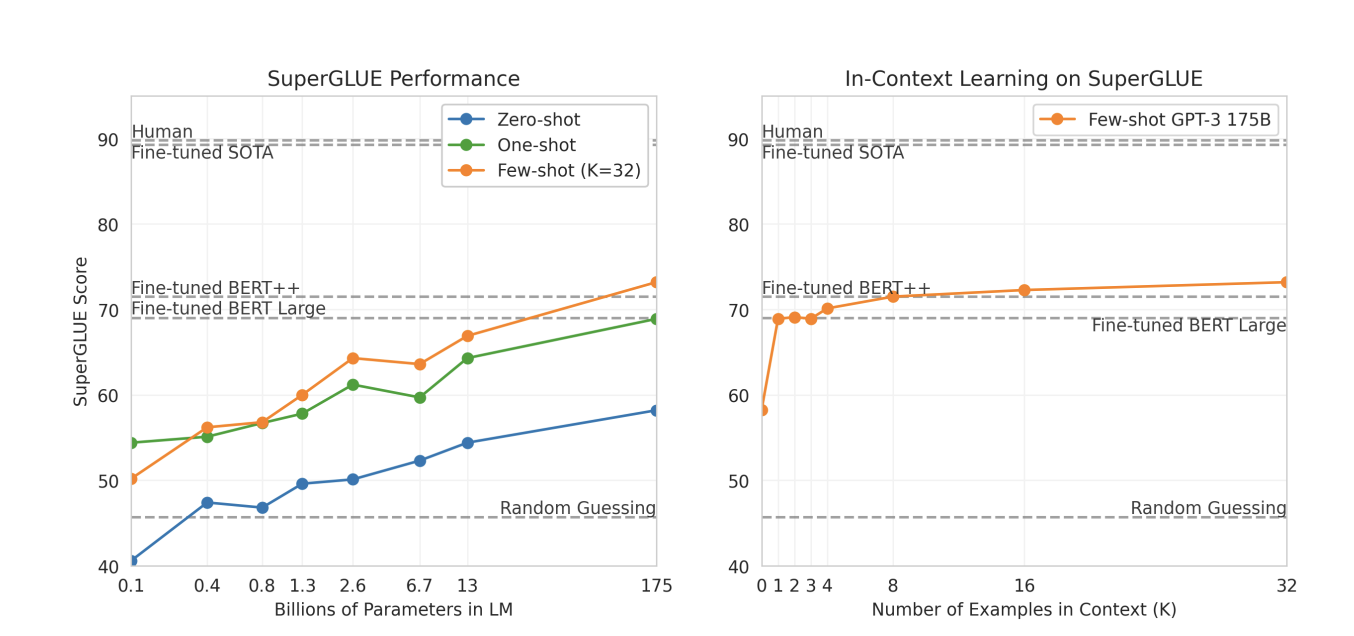
Super GLUE
자연어 이해(NLU)의 종합적 능력을 평가하는 고난이도 벤치마크
다양한 언어 과제 포함 (추론, 상식, 문장 유사도, 질의응답 등)
AI 모델의 종합적인 언어 이해 능력 테스트
- 평가 방식: Zero-shot, One-shot, Few-shot 세 설정에서 모두 테스트
- GPT-3는 대부분의 SuperGLUE 하위 과제에서 few-shot 설정 시 점진적으로 향상된 성능 보임
- GPT-3 175B 모델, few-shot 기준에서 일부 과제에서는 fine-tuned 모델에 근접 또는 능가

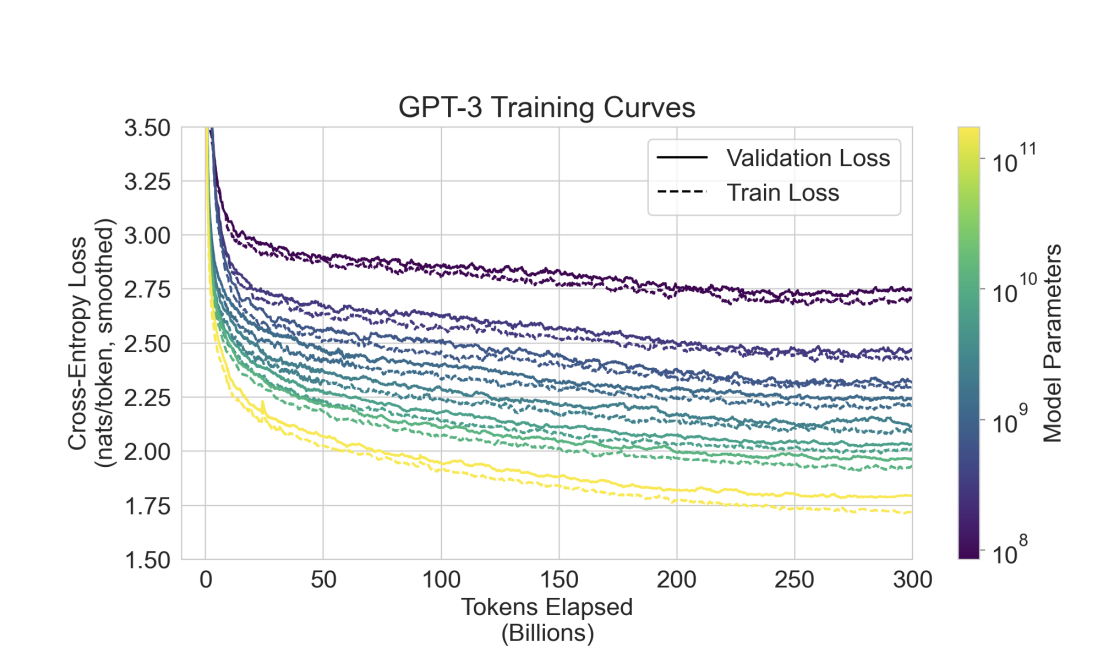
GPT-3는 정말 데이터를 ‘암기’했을까?
Figure 4.1: Training vs. Validation Loss로 보는 메모라이제이션 분석
아래 그래프는 GPT-3의 학습 과정에서 측정된 Train Loss(점선)와 Validation Loss(실선)를 모델 크기별로 보여줌.
1. 과적합(overfitting)의 흔적이 없다
- 일반적으로 모델이 데이터를 ‘암기’하면, 훈련 손실은 빠르게 낮아지지만 검증 손실은 줄지 않거나 오히려 증가
- 하지만 GPT-3의 곡선에서는 Train과 Validation 손실 간 간격이 일정하고 작게 유지됨
- 즉, 모델이 훈련 데이터만 외운 것이 아니라, 일반적인 언어 패턴을 학습했음을 시사
2. 모델이 커질수록 성능은 부드럽게 향상
- 파라미터 수가 많을수록(색상이 밝을수록) 손실이 꾸준히 감소
- 이 패턴은 스케일링 법칙(Power-law scaling)과도 일치하며, 단순한 용량 증가가 학습 성능을 예측 가능하게 향상시킨다는 근거가 됨
3. 3000억 토큰 동안 학습이 계속 유의미하게 진행됨
- 학습이 후반부로 가도 손실은 완만하게 계속 줄어듦
- 이는 모델이 아직 일반화 가능한 정보를 더 많이 학습하고 있음을 의미함
데이터 오염(Data Contamination)과 관련된 분석
아래는 클린 데이터만으로 평가할 때 성능이 더 좋았는가?”를 시각화한 도표
- X축 (가로): 해당 데이터셋에서 클린(clean) 데이터의 비율 (%)
- 0%: 거의 전부 오염된 데이터
- 100%: 거의 전부 클린 (중복/유출 없이 순수한 테스트셋)
- Y축 (세로): 성능 변화율 (Accuracy / F1 / BLEU 등)
기준: 전체 데이터로 평가했을 때 대비,
- 양수(+): 클린 데이터만 평가했을 때 더 나은 성능
- 음수(−): ‘더티(dirty)’ 데이터 포함했을 때 성능이 더 좋았음

해석 포인트
1. 대부분의 데이터셋은 클린 평가와 큰 차이 없음
- 다수의 점들이 Y=0 근처에 몰려 있음
→ 클린 데이터와 전체 데이터 간 성능 차이가 거의 없음
→ GPT-3가 데이터셋을 암기한 것이 아니라, 일반화 했다는 증거
2. 일부 데이터셋은 클린 데이터에서 더 좋은 성능 (위쪽 점들)
예: QuAC, Symbol Insertion
- 오히려 ‘더티’한 데이터가 포함되었을 때 혼란을 줬을 가능성 있음 → 깨끗한 평가 환경이 진짜 실력을 더 잘 반영함
📉 3. 일부 데이터셋은 더티 데이터 포함시 성능이 더 좋음 (아래쪽 점들)
예: DROP, Reversed Words
- 평가셋 일부가 훈련 데이터에 포함되었을 가능성 → 성능이 부풀려졌을 수 있음 (데이터 오염의 부작용)
결론
GPT-3는 대부분의 과제에서 테스트 데이터를 ‘암기’한 것이 아니라, 일반화 학습을 통해 성능을 낸 것으로 보이며, 일부 데이터셋에서는 데이터 오염이 성능에 영향을 줄 수 있음을 시각적으로 보여준다.
Limitation
1. 텍스트 생성 품질 한계
- 문서 전체에서 의미 중복, 맥락 붕괴, 논리 불일치, 비논리적 문장이 종종 발생
- 긴 글일수록 일관성 유지에 실패할 가능성 증가
2. 상식 물리 취약
- PIQA 등 일부 데이터셋은 잘 처리하지만,
- 예: “치즈를 냉장고에 넣으면 녹을까?” 같은 질문엔 종종 틀린 답변
- 물리적 직관 부족이 드러남
3. 일부 NLP 태스크 성능 저조
- WIC, ANLI, 일부 Reading Comprehension 과제에서 one-shot/few-shot 성능이 낮음
- 문장 비교, 의미 유사성 판단 등에서는 거의 랜덤 수준의 정확도
4. 구조적 제약 (Autoregressive 모델의 한계)
- GPT-3는 단방향(왼→오) 언어모델
- 반면, BERT류 양방향(bidirectional) 모델은 일부 태스크에서 더 나은 성능을 보임
- 특히 빈칸 채우기, 문장 간 비교, 긴 문장 이해 후 요약 등에서는 불리
5. 사전학습 목표의 한계
- 모든 토큰을 동일하게 예측함 → 중요한 정보에 집중하지 못함
- 예측 기반만으로는 실제 목표 지향적 시스템(예: 가상비서)에 한계
- 다중 모달 학습, 강화학습, 인간 피드백 기반 학습 등이 대안으로 제시됨
6. 비효율적인 학습
- 인간은 평생 수십억 토큰도 접하지 않지만, GPT-3는 3000억 토큰을 학습
- 표본 효율(sample efficiency) 측면에서 개선 필요
7. Few-shot 학습의 실체에 대한 불확실성
- GPT-3가 정말 새로운 작업을 즉석에서 학습하는가? 아니면
- 훈련 중 유사한 작업을 단순히 ‘인식’하는 것인가?는 아직 불명확
8. 현실적 사용의 어려움
- 모델이 너무 크고, 추론 비용이 매우 높음
- 해결책: 작은 모델로 distillation (지식 증류) → 하지만 GPT-3 크기에선 아직 시도되지 않음
9. 해석 불가능성과 편향
- 모델 결정 과정은 불투명
- 낯선 입력에 대한 반응은 신뢰성 낮고 예측 불안정
- 훈련 데이터에 내재된 편향(bias)을 그대로 반영해 차별적·편향된 생성 가능성
'딥러닝, 논문 리뷰' 카테고리의 다른 글
| [딥러닝, 검색엔진] HNSW, IVFFlat 바닥부터 탐색하기 (Vector Search) (2) | 2025.07.27 |
|---|---|
| [딥러닝, 정보 이론] KL Divergence와 엔트로피 완전 정복 (2) | 2025.06.09 |
| [딥러닝, 논문리뷰] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (1) | 2025.03.20 |
| [딥러닝, 논문리뷰] LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS - 양자화 (1) | 2025.03.04 |
| [딥러닝, 논문리뷰] Attention Is All You Need 3 - Residual Connection, 나머지 내용들 (1) | 2025.03.04 |