시작 전에..
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org
해당 포스팅은 논문을 읽으며 공부한 내용들은 정리하였음
0.Abstract
- BERT란?
- 트랜스포머 기반 양방향 인코더로 새로운 언어 표현 모델, 기존 언어모델과는 다르게, 왼쪽과 오른쪽 문맥을 동시에 고려하는 양방향 비지도 학습
작업에 따른 성능 요약 및 비교
BERT 성능 요약 및 비교
| 작업 | 기존 모델 성능 | BERT 성능 | 절대 향상 | 설명 |
|---|---|---|---|---|
| GLUE 점수 | 72.8% | 80.5% | +7.7% | GLUE 벤치마크(General Language Understanding Evaluation)에서 전반적인 성능 평가. |
| MultiNLI 정확도 | 82.1% | 86.7% | +4.6% | Multi-Genre Natural Language Inference: 문장 간 관계 추론 작업. |
| SQuAD v1.1 F1 | 91.7 | 93.2 | +1.5점 | SQuAD(Stanford Question Answering Dataset) v1.1: 질문 응답 정확도(F1). |
| SQuAD v2.0 F1 | 78.0 | 83.1 | +5.1점 | SQuAD v2.0: 답이 없는 질문에 대응하는 질문 응답 정확도(F1). |
- GLUE 점수
- 다양한 자연어 처리 과제를 포함한 종합 벤치마크,
BERT는 기존대비 7.7% 향상된 80.5% 달성
- 다양한 자연어 처리 과제를 포함한 종합 벤치마크,
- MultiNLI
- 문장 간 추론 작업에서 기존 대비 4.6% 향상된 86.7% 정확도.
- SQuAD v1.1
- 답이 없는 질문 처리 능력까지 포함한 데이터셋에서 기존 대비 5.1점 향상된 83.1.
1.Introduction

BERT의 구조
- 사전 학습(Pre-training):
- BERT 모델은 다양한 사전 학습 작업에서 레이블이 없는 데이터로 학습됨.
- 학습 과정에서는 양방향 텍스트 표현을 학습하며, 문맥 내에서 단어의 의미를 더 깊게 이해할 수 있도록 설계 .
- 미세 조정(Fine-tuning):
- 사전 학습 된 파라미터를 기반으로, 다운스트림작업(질문 응답, 언어 추론 등)에서 모든 파라미터를 업데이트함
- 각 작업은 고유한 데이터로 미세 조정되지만, 동일한 사전 학습 된 파라미터로 초기화 함
BERT의 가장 높은 성능의 비결은?
레이블이 없는 방대한 데이터를 토대로 사전 훈련된 모델을 생성한 이후, 레이블이 있는 다른 작업에서 추가 훈련(파인튜닝)을 통해 하이퍼 파라미터를 재 조정하여 BERT를 사용하기 때문에 성능이 좋을 수 밖에 없는 것
쉽게 말해서 다방면으로 응용 동작이 가능하게끔 기초 훈련이 잘되어있단 것이다.
BERT의 특징
- 다양한 작업에 걸쳐 통일된 구조
- 그로인해 안정성 있는 뼈대로 문장단위의 Task(NLI 등)에 두각을 보임
모델 아키텍처
- 다층 양방향 Transformer 인코더로 구성되어 있음
- 아키텍처 요약
- \(L\) : 레이어의 개수
- \(H\) : 은닉 의 크기
- \(A\) : Self-Attentiondml 수
BERTBASE : \(L\) : 12, \(H\): 768, \(A\): 12, \(Total Parameters\) : 110
BERTLARGE : \(L\) : 24, \(H\): 1024, \(A\): 16, \(Total Parameters\) : 340
으로 구성된 결과물을 보여줌
- 양방향을 사용하여, GPT(디코더 → 왼쪽에서 오른쪽으로)처럼 단방향 제한을 두지 않고 문맥을 동시에 학습하는 특징을 가지게 됨
🔑 Input / Output Representations
BERT가 다양한 다운스트림 태스크는 두 개의 문장 사이의 관계를 이해하는 것이 핵심이다(QA, NLI와 같은), 이런 문장 사이의 관계는 기존의 언어모델로는 알아내기가 굉장히 힘들었는데 이를 학습하기 위해 NSP, MLM을 학습 과제로 사용한다.
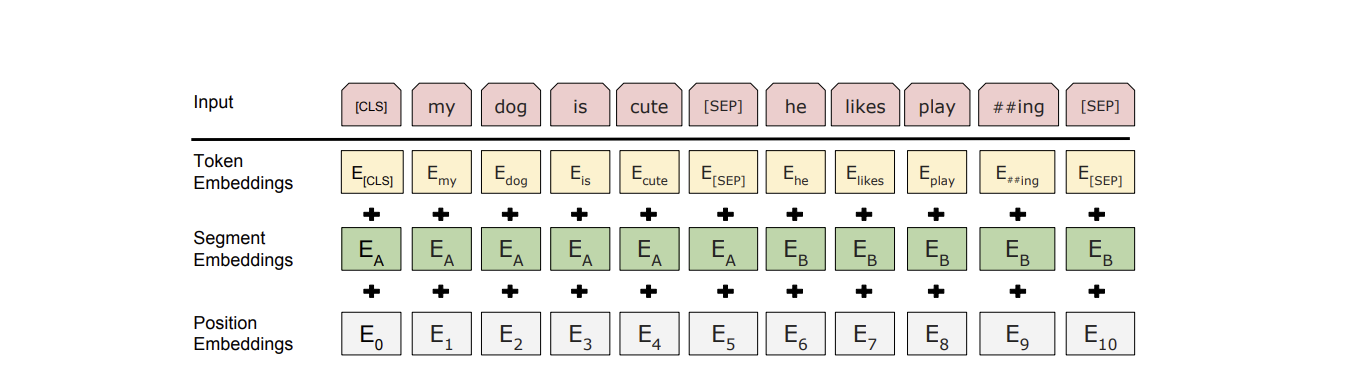
문장의 쌍은 하나의 시퀀스로 함께 묶인다. 그리고 이 쌍을 두 가지 방법으로 문장을 구별한다.
먼저, 토큰 [SEP]을 통해 기존의 문장들을 분리를 보여준다. 두 번째로 우리는 모든 토큰에 이것이 문장 A인지 B인지 표시하는 학습된 임베딩을 추가한다.
모든 문장의 첫 번째 토큰은 항상 [CLS]이다. 이 토큰을 통해 마지막의 분류를 해줄 때에 분류에 대한 값이 이 토큰의 연산 결과로 나타나게 된다.
BERT 연산구조
- tokenizer embedding : 실질적인 입력이 되는 워드 임베딩, 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개
- Segment Embedding : 위치 정보를 학습하기 위한 임베딩(트랜스포머의 그 포지셔널 인코딩이라고 보면 될 것 같다), 임베딩 벡터의 종류는 문장의 최대 길이인 512개
- Position Embedding : 두 개의 문장을 구분하기 위한 임베딩, 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
참고로 BERT의 사용하는 토크나이저는 워드피스 임베딩 방식 추후 정리할 예정
결론
- 버트는 총 3개의 임베딩 층을 사용
NSP
문장의 쌍은 하나의 시퀀스로 묶인다, 이러한 시퀀스를 먼저 토큰[SEP]을 통해 기존의 문장들의 분리를 보여준 후 A, B로 나누었을 때 첫 번째 문장(A)와 두 번째 문장(B)가 연속적인 관계인지 예측하는 작업(IsNext, NotNext)
위 작업은 NLI, QA등의 작업에서 유용하게 작용함
- 학습 데이터 구성
- 50%: 문장 B가 실제로 문장 A 다음에 오는 문장.
- 라벨: IsNext
- 50%: 문장 B가 랜덤하게 선택된 문장.
- 라벨: NotNext
- BERT의 처리
- BERT는 전체 입력 시퀀스를 처리하고, 최종적으로 [CLS] 토큰의 은닉 상태를 사용해 문장 간 관계를 예측.
- 출력
- \(P(\text{IsNext}\)): 문장 B가 문장 A 다음에 오는 실제 문장일 확률.
- \(P(\text{NotNext}\)): 문장 B가 랜덤하게 선택된 문장일 확률.
Masked LM
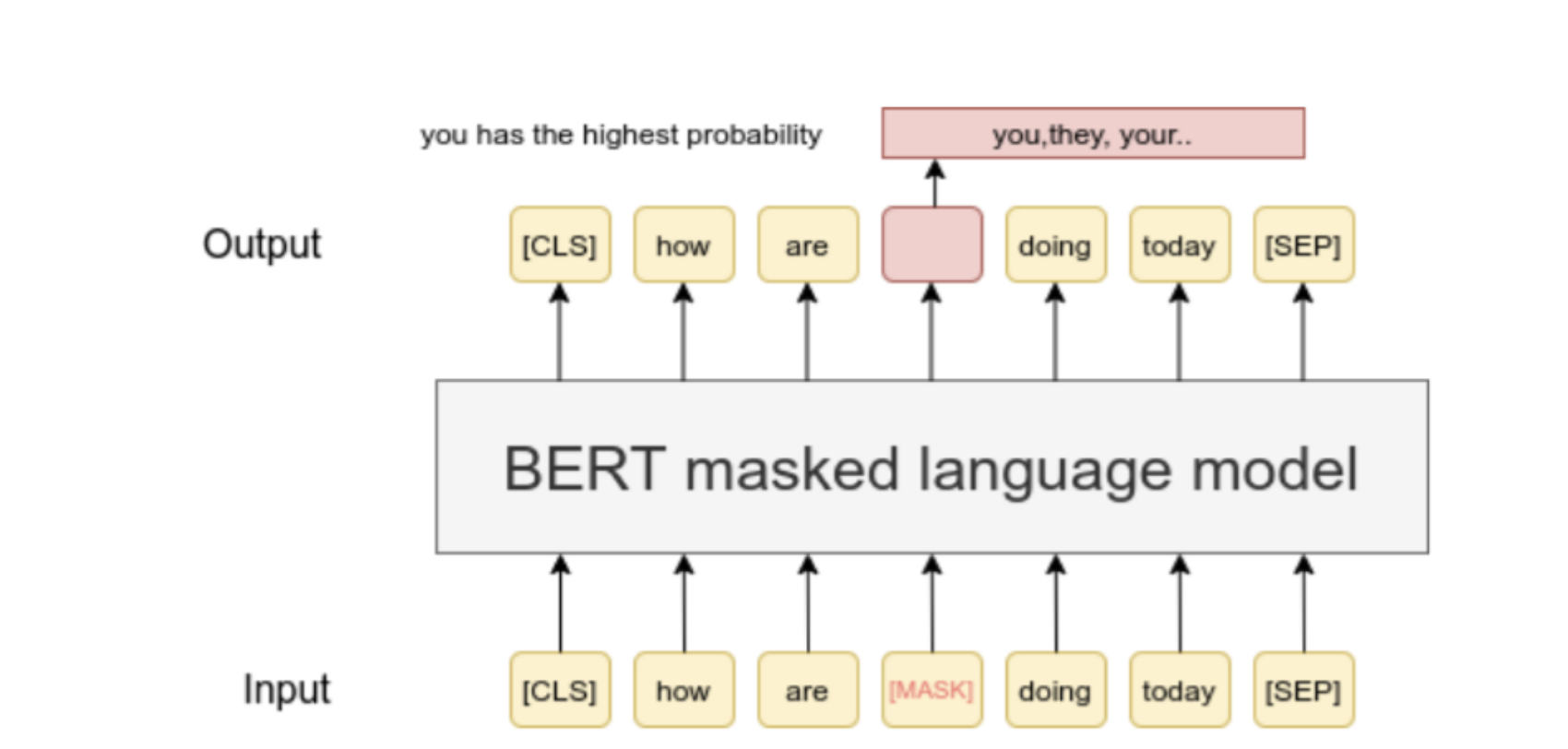
- 멀티 레이어 구조에서의 예측 단어는 자칫하면 과적합 가능성 해당 가능성을 고려하기 위해 워드토큰의 15% 값을 무작위로 각 시퀀스별로 마스킹 시킨후 섞여진 단어 내에서 단어를 예측하는 것을 목표로 함
쉽게 생각해서 우리 외국어 영역에서 했던 빈칸추론과도 비슷한 느낌
예)
"나는 오늘 [MASK]에 갑니다."학습 과정:
- 모델은 [MASK]를 주변 문맥(“나는”, “오늘”, “갑니다”)을 기반으로 예측.
- 예측 결과:
- “학교” (확률 0.85)
- “공원” (확률 0.10)
- “병원” (확률 0.05)
- 출력:
- 모델은 [MASK]를 “학교”로 예측(확률 85%).
- 이를 통해 양방향 학습이 가능하지만, 파인튜닝 중에는 MASK 토큰을 사용하지 않기에 사전 훈련과 파인튜닝간의 불일치를 만들어낼 수 있는 단점이 존재하기는 한다.
KoBERT를 통한 한국어 감정분석
- 설계 과정은 그렇게 순탄하지 못했다
설계 어려웠던 이유
- 토크나이징 오류
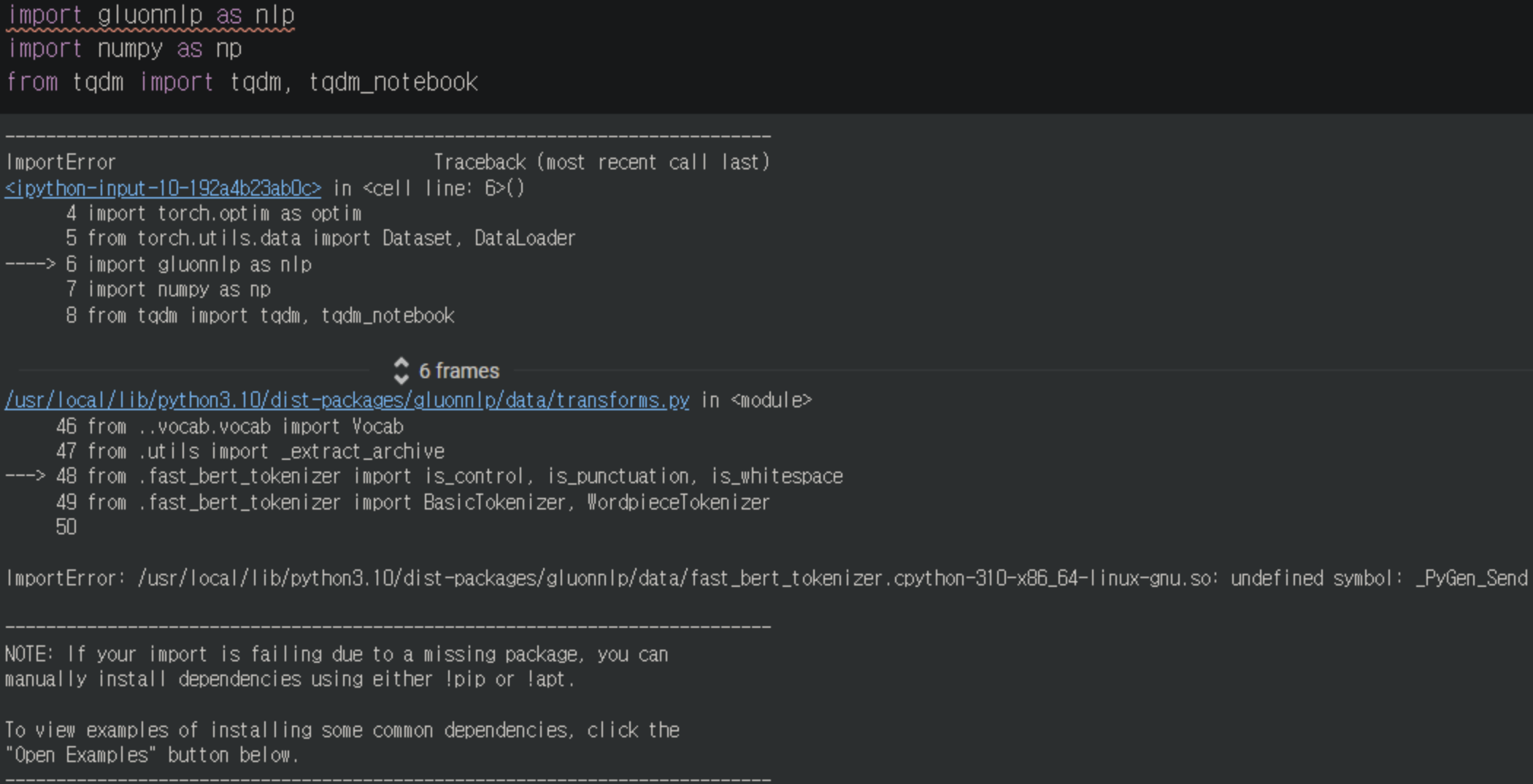
- SKT KoBERT의 문자열 전처리인 토크나이저를 사용하기 위해 필요한 glounnlp, mxnet이 버전 문제로 인해 충돌 이슈 발생 → 기존 3.10 버전이 아닌 5년전 오래된 모델로 3.8 버전에서의 호환이 가능했기에 버전 충돌이 주된 문제였다
- 가비지 인 가비지 아웃


상태가 그렇게 좋진 않았다
왜 그런진 모르겠지만... 일단 한 번 데이터셋을 확인해보았다

학습하기에 뭔가 적절한 표현이 맞지 않는 문장들이 많아, 다른 데이터셋을 수집하여 학습하기로 하였고 그 결과 한 블로그를 통해 데이터셋을 얻게 되었다
[파이썬]KoBERT로 다중 분류 모델 만들기 - 데이터셋 다운로드
[파이썬]KoBERT로 다중 분류 모델 만들기 - 데이터셋 다운로드 위 프로젝트에서 사용된 AIHUB 데...
blog.naver.com

학습 아키텍처
- Hugging Face Trainer 함수 이용
- KoBERT Tokenizer 클래스를 적극 활용하여 토크나이저 수동 저장
- monologg/kobert의 모델을 파인튜닝하기로 결정
# 7가지 감정 라벨을 model config에 세팅을 해줌
from datasets import Dataset
from transformers import BertConfig, BertForSequenceClassification, AutoTokenizer
import torch
# 감정별 라벨 매핑
label2id = {
"공포": 0,
"놀람": 1,
"분노": 2,
"슬픔": 3,
"중립": 4,
"행복": 5,
"혐오": 6,
}
id2label = {v: k for k, v in label2id.items()}
# BertConfig에 라벨 매핑 추가
config = BertConfig.from_pretrained(
"monologg/kobert",
num_labels=7,
id2label=id2label,
label2id=label2id
)
model = BertForSequenceClassification.from_pretrained("monologg/kobert", config=config)
tokenizer = KoBertTokenizer.from_pretrained("monologg/kobert")모델은 트랜스포머 라이브러리 내 버트 전용 분류 모델로 구별시키는 BertForSequenceClassification와 KoBertTokenizer를 사용
여기서 KoBertTokenizer는 어디서 가져왔는지?
!git clone https://github.com/monologg/KoBERT-Transformers.git
https://github.com/monologg/KoBERT-Transformers.git
GitHub - monologg/KoBERT-Transformers: KoBERT on 🤗 Huggingface Transformers 🤗 (with Bug Fixed)
KoBERT on 🤗 Huggingface Transformers 🤗 (with Bug Fixed) - monologg/KoBERT-Transformers
github.com
kobert_transformers.tokenization_kobert의 디렉토리 루트를 따고 가시면 있다
그렇게 생성된 토크나이저를 통해 데이터셋을 변환
import json
with open('/content/train_datasets.json', 'r', encoding='utf-8') as files:
train_dataset = json.load(files)
with open('/content/test_datasets.json', 'r', encoding='utf-8') as files_t:
val_dataset = json.load(files_t)
from datasets import Dataset
# 리스트 데이터를 Hugging Face Dataset으로 변환
train_dataset = Dataset.from_list(train_dataset)
val_dataset = Dataset.from_list(val_dataset)
# 토큰화 함수 정의
def tokenize_function(examples):
return tokenizer(
examples['Sentence'], # 텍스트 필드 이름
padding='max_length',
truncation=True,
max_length=128
)
train_dataset = train_dataset.map(tokenize_function, batched=True)
val_dataset = val_dataset.map(tokenize_function, batched=True)
# 불필요한 컬럼 제거
train_dataset = train_dataset.remove_columns(['Sentence'])
val_dataset = val_dataset.remove_columns(['Sentence'])
# 데이터셋 포맷 지정 (PyTorch tensors)
train_dataset.set_format('torch')
val_dataset.set_format('torch')
그렇게 만들어진 데이터셋을 보면
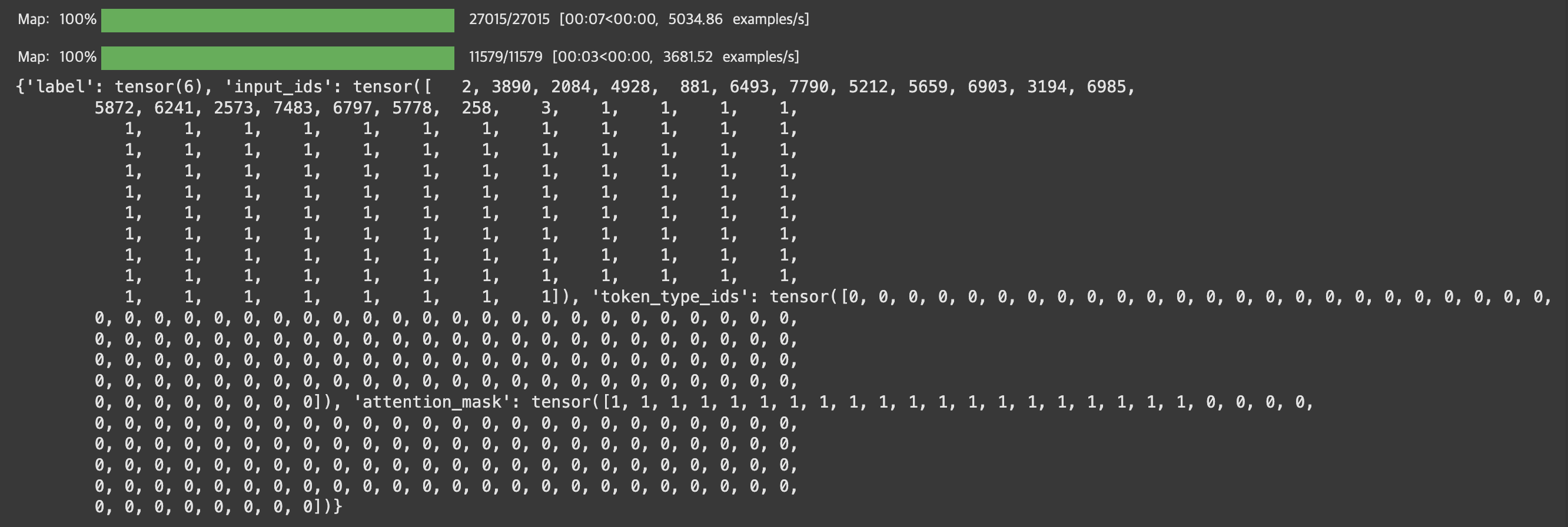
모델의 Config 매핑 확인

그후 평가 지표 값을 세팅해준다.
from sklearn.metrics import f1_score, precision_score, recall_score
def compute_metrics(p):
preds = p.predictions.argmax(-1) # 예측된 클래스
labels = p.label_ids # 실제 라벨
f1 = f1_score(labels, preds, average='macro')
precision = precision_score(labels, preds, average='macro')
recall = recall_score(labels, preds, average='macro')
return {
'f1_macro': f1,
'precision_macro': precision,
'recall_macro': recall
}
마무리로 Trainer 함수를 통해 세팅하고나서 구워주면 끝
from transformers import BertConfig, BertForSequenceClassification, TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir='./results',
learning_rate=2e-5,
per_device_train_batch_size=64,
per_device_eval_batch_size=1,
num_train_epochs=5,
eval_strategy="epoch",
save_strategy="epoch",
metric_for_best_model='f1_macro',
load_best_model_at_end=True,
fp16=True, # Mixed Precision 활성화
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()모델 훈련 결과

입력 데이터를 통한 인퍼런스
texts = [
"오늘 정말 기분이 좋다 ㅎㅎ!",
"왜 이렇게 힘든 일이 많지? ㅠㅠ",
"정말 화가 난다!",
"평범한 하루였어.",
"너무 재밌다 ㅋㅋㅋ!",
]
결론
그렇지만 중립적 표현이 다소 문맥을 유추하지 못하는 결과를 볼 수 있다 → 평범한 하루였어 : 슬픔(?) 등
- 더 나은 모델인 KcBERT, KoELECTRA를 사용할지, 아니면 데이터 전처리에 조금 더 비중을 들지는 하이퍼파라미터 조정을 하고 난 뒤에 결정해볼 생각이다.
- BERT는 오래전에 고안된 모델이지만, 현재 대형 LLM 모델의 시초라고 할 수 있을만큼 중요한 모델이니만큼 개념은 확실하게 알고갈 필요가 있어 논문 리뷰 및 실질적인 실습을 진행하였다.
끝
'딥러닝, 논문 리뷰' 카테고리의 다른 글
| [딥러닝] RNN, LSTM, GRU Sequence - 1 (2) | 2024.12.27 |
|---|---|
| [딥러닝] AutoEncoder란? - 신경망 아키텍처 (1) | 2024.12.20 |
| [딥러닝] 손실함수의 종류 및 정의(Loss Function) (5) | 2024.12.16 |
| [딥러닝] 분류모델 성능 평가지표 (5) | 2024.12.12 |
| [딥러닝] 활성화 함수의 종류와 역할 (2) | 2024.12.11 |