이전 시간에 내용을 정리하던 와중에 갑자기 생각난게 있다.
Q, K, V 로직중에서 Q랑 K는 그럼 같은 얘기 아닌가?
그리고 어텐션 스코어는 왜 저렇게 계산하는걸까?
아무리 찾아봐도 내가 이해가 안돼서 이해가 될 때까지 계속 정리하려고 한다.

처음 찾아 본 \(Query\) 와 \(Key\)의 값은 각각 "입력 단어를 임베딩한 값", "입력한 단어의 문맥적 특징을 통해 추출된 임베딩 값" 이 두가지로 나뉠 수 있다.
문맥적 특징이 뭘까?
1. 기본적으로 \(Query\) 값은 입력된 단어의 임베딩 값에 가중치 행렬 ( \(W_Q\) ) 를 곱해 생성된 값이라고 보면 됩니다.
2. 이 변환을 통해 메커니즘은 특정 단어의 "관심사"를 학습할 수 있습니다.
여기서 잠깐
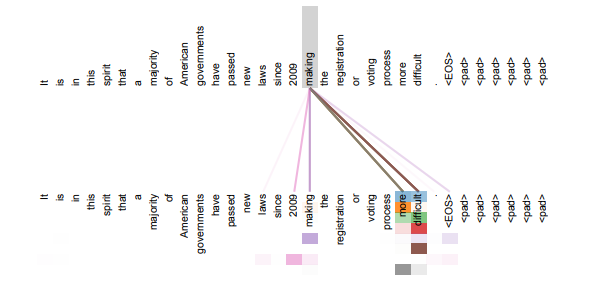
결국 어텐션이 탄생한 이유 자체로서 거슬러 올라간다면, 입력 단어 중 중요한 단어에 집중하기 위해 설계되었단 사실을 훑어봤을 때
상기 문맥에 대한 내용에 있을 "관심사"에 대한 학습을 왜 하는지에 대해서 이해할 수 있을 것이다.
그래서 이해를 다시 하기 위한 예제를 준비해봤다.
1. 입력된 단어의 임베딩 생성
\(나는 → [0.1, 0.2, 0.3, 0.4], 피자가 → [0.5, 0.6, 0.7, 0.8]....\)
2. \(Q, K, V\) 벡터 생성
1. \(Query(Q)\)
- 특정 단어가 "무엇에 더 관심을 가지고자 하는지"를 표현하기 위해 생성
- 각 단어의 가중치 행렬 \(W_Q\)를 곱한 후 생성
\(Q['나는'] = Embedding['나는'] ⋅ W_Q\)
2. \(Key(K)\)
- 입력된 단어 벡터와 똑같이 입력되나, 단어 의미의 문맥적 표현을 하기 위해 계산
- 각 단어의 임베딩에 가중치 행렬 \(W_K\)를 곱한 후 생성
\(K['나는'] = Embedding['나는', '피자가', '먹고' '싶다'] ⋅ W_K\)
3. \(Value(V)\)
- 실제 정보를 포함하여, \(Q 와 K를\) 통해 강조된 정보를 제공,
각 임베딩에 \(W_v\)를 곱해 생성
\(\text{Attention Output}['나는'] =\) \(\sum_{j} \alpha_{ij} V_j\)
- \(\alpha_{ij}\) : "나는"으로 들어간 입력 벡터 \(j\)와 얼마나 관련이 있는지 나타내는 확률
3. 소프트 맥스를 통한 정규화
1. 그렇게 구한 \(Q,K\)의 값을 소프트 맥스를 통해 확률 값으로 변환
\( \alpha_{ij} = \text{Softmax}\left(\frac{\text{Score}_{ij}}{\sqrt{d_k}}\right) \)
2. Value 벡터를 조합
- 확률값으로 연산한 값을 통해 V의 가중치를 적용 시키면 된다.
\(\text{Attention Output}['나는'] =\) \(\sum_{j} \alpha_{ij} V_j\)
핵심 이해
1. \(Q, K\)를 유사도를 계산하여 가중치 생성
2. 소프트맥스 : \(Q,K\)의 유사도를 정규화 한 후, 확률 가중치 \(\alpha\) 생성
3. \(V\) : 입력 문장의 모든 단어 정보를 포함하여, \(\alpha\)를 적용 시킨 후에 최종 어텐션을 위한 출력 정보를 만듬.
** 별책부록 **
\(Q와 K\)를 계산하는 수식?
\(Score_{ij} = Q_i \cdot K_k^T \)
가중치 행렬이란?
- \(Q, K,V\) 벡터를 생성하기 위해 사용되는 학습 가능한 행렬
- 입력 임베딩의 벡터(고정된 차원 \(\text{d_model}\)를 어텐션 차원 \(\text{d_attention}\)으로 변환 합니다.
역할
- 벡터 공간 변환
- 입력 임베딩 벡터가 \(\text{d_model}\) 차원일 때 , 가중치 행렬은 \(\text{d_attention}\) 차원으로 변환합니다.
- 예시 : \(\text{d_model} = 512\) , \(\text{d_attention} = 64\)라면
\(W_Q=W_K=W_V = R^{512*64}\)
예제)
"나는" 의 입력이 들어간 벡터
\([0.1, 0.3, 0.5, 0.7]\)
단어 집합의 크기가 2, 임베딩 차원의 4라고 가정한다고 한다면
$$
WQ =
\begin{bmatrix}
0.1 & 0.3 & 0.5 & 0.7 \\
0.2 & 0.4 & 0.6 & 0.8 \\
\end{bmatrix}
$$
위의 식과 계산하여 나오는 것이 입력 값과 가중치 값의 합이다.
결론
어텐션 스코어는 Query와 Key 벡터 간의 내적을 통해 계산되며, 이를 스케일링하고 소프트맥스를 적용하여 각 Value 벡터에 대한 중요도를 반영한 가중합을 구합니다. 이 과정을 통해 모델은 입력 데이터 내에서 중요한 부분에 집중할 수 있게 되며, 효과적인 정보 처리가 가능해집니다.
'딥러닝, 논문 리뷰' 카테고리의 다른 글
| [딥러닝] 최적화와 경사하강법 Deep Dive(모멘텀, AdaGrad, RMSProp, NAG, Adam) - 2 (1) | 2025.01.17 |
|---|---|
| [딥러닝] 최적화와 경사하강법 Deep Dive(배치 경사하강법, 확률적 경사하강법) - 1 (0) | 2025.01.16 |
| [딥러닝] Attention Machanism 밑바닥부터 들어가기 - Deep Dive Sequence - 3 (1) | 2025.01.13 |
| [딥러닝 논문리뷰] Seq2Seq 메커니즘 Sequence - 2 (1) | 2025.01.10 |
| [딥러닝, 논문리뷰] Meta - Memory Layers at Scale (0) | 2025.01.04 |