Attention 메커니즘을 이해하기 위해 기본적으로 알고 있어야 할 RNN 구조와 LSTM 그리고 Seq2Seq는 간단하게만 작성 후 바로 본론으로 들어가겠습니다.
기본 연산
- RNN

- 이전 출력 값이 현재 결과에 영향을 미치는 계산 방식 (시퀀스 및 메모리 셀이라고도 불립니다.)
- 현재의 은닉층 값 \(h_t\)은 input \(x_t\)와 직전 은닉층 \(h_{t-1}\)을 입력으로 받음
- \(W_{hh}\)와 \(W_{xh}\) 는 직전 은닉층의 \(x\)의 가중치 값(행렬)임
- 이러한 구조를 통해 하이퍼볼릭 탄젠트를 활성화 함수로 계산을 함
- LSTM
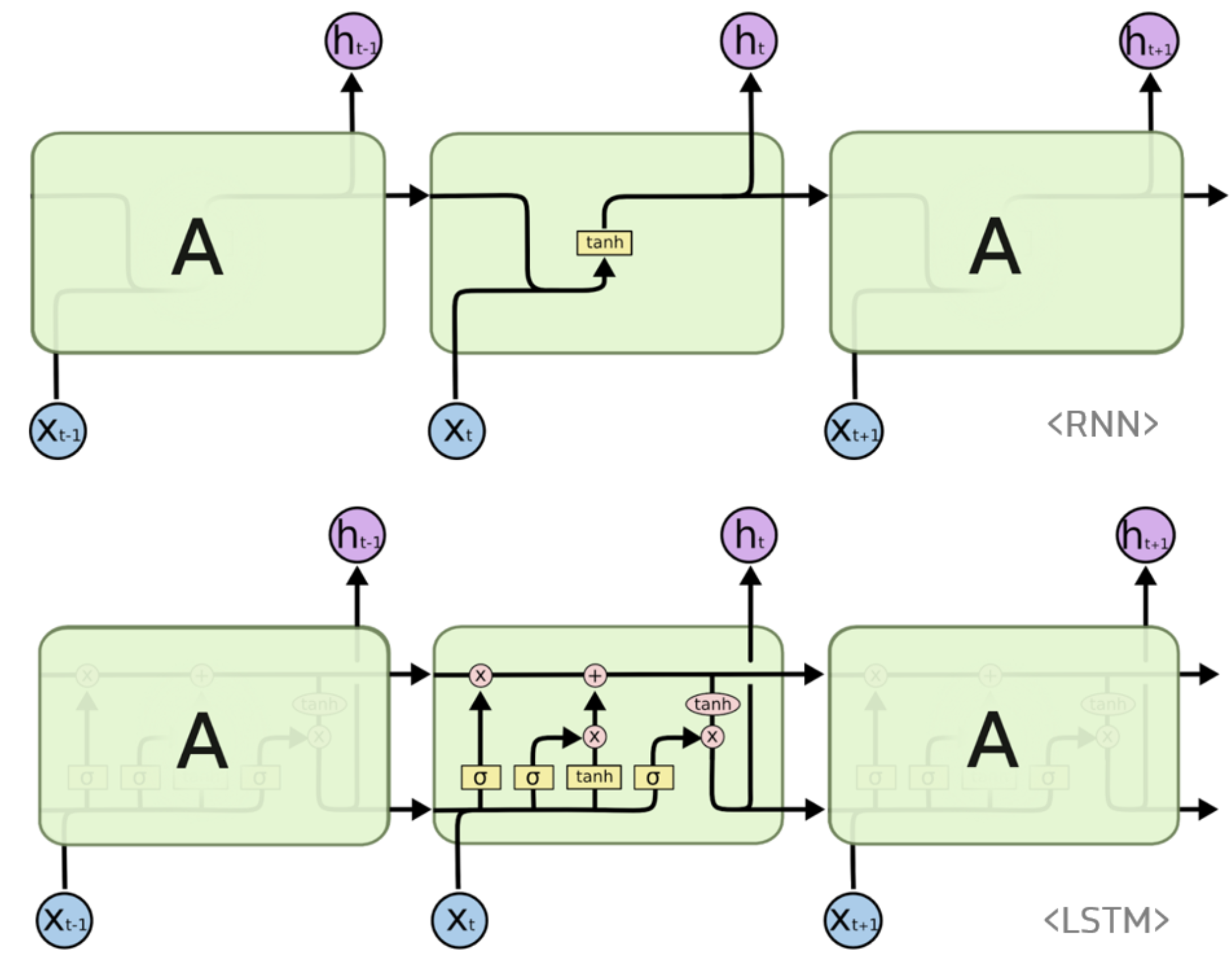
- 기존의 단방향 구조의 고질적 문제인 장기 기억 의존 문제를 해결하기 위해 제안된 방법 중 하나
- `Cell State`라는 방법으로 기억해야 할 중요한 가중치 값과 버려도 될 가중치 값을 구분하는 2가지 방법을 사용(망각, 입력)
- 입력이 들어왔을 때, 망각 게이트 안에서 이미 계산된 은닉층의 값 \(h_{t-1}\) 과 현재 입력 가중치가 들어가 있는 \(W_t\) 을 결합
- 특징으로는 입력 게이트에 들어가기 전 \(Sigomid\) 함수를 통해 특정 임계치에 포함이 되는지 안 되는지로 후보군 선별
- 그렇게 후보 게이트는 입력 게이트에 새로운 정보를 입력하기 전 생성을 위해 하이퍼볼릭 탄젠트를 통해 연산 후 최종 입력 게이트로 이동하게 됨
- 이러한 과정을 통해 시그모이드 함수를 통해 입력 게이트에서 연산을 하고 그 은닉층을 통해 최종 출력으로 나오게 됨 → 손실 함수로 로스 값 계산
- Seq2Seq
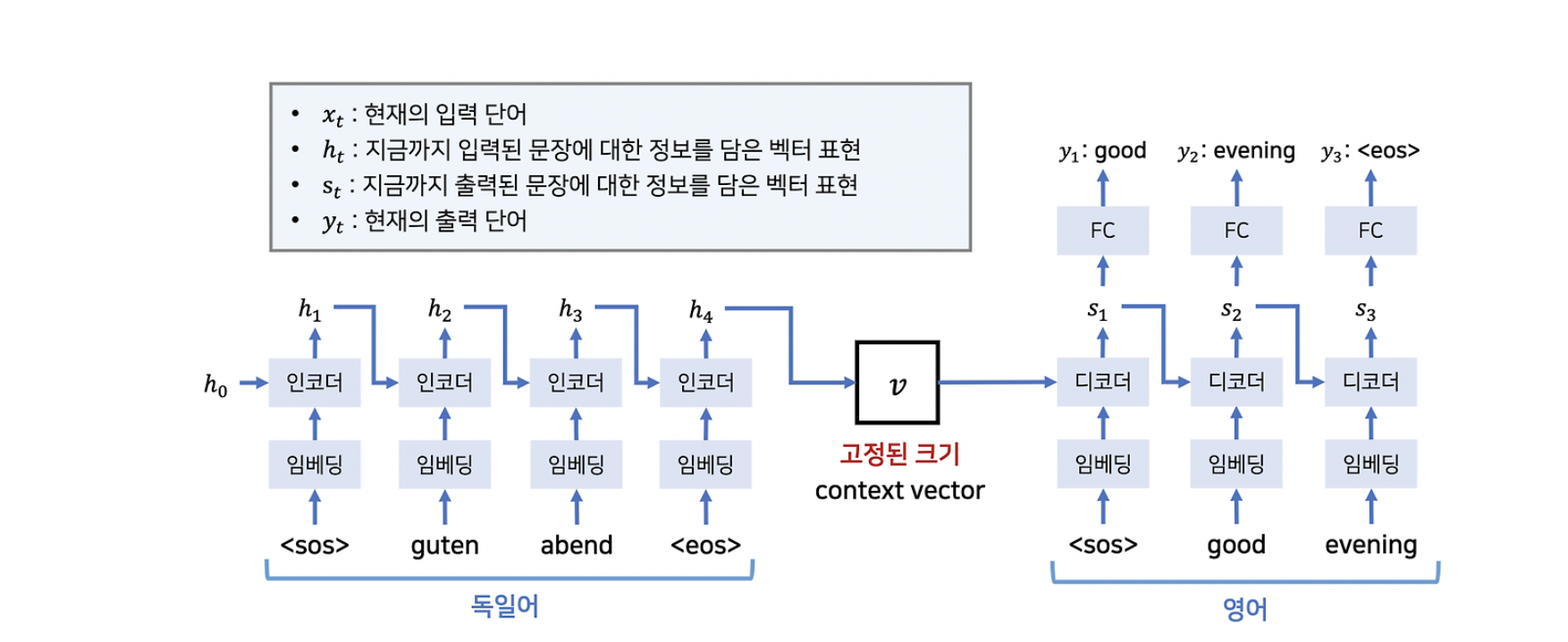
- 2개의 언어 모델을 기반으로 기계번역을 조금 더 유리하게 작용 시키기 위해 시작된 방법
- `Encoder` 부문에 언어모델 1개(\(RNN\), `LSTM`) `Decoder` 부문에 언어모델 1개를 각각 부여하여 각각 문맥을 이해하고 그 에따른 반대 되는 언어를 생성하기 위해 만들어짐
추론 방식
입력 시퀀스 (인코더):
- 입력: "나는 학교에 간다"
- 토큰화된 입력: [나는, 학교에, 간다]
출력 시퀀스 (디코더):
- 출력: "I go to school"
담긴 데이터
| 단어 | 히든 스테이트 ((h_i)) |
|---|---|
| 나는 | \(h_1\) = [0.1, 0.3, 0.5]) |
| 학교에 | \(h_2\) = [0.2, 0.1, 0.4]) |
| 간다 | \(h_3\) = [0.7, 0.8, 0.9]) |
- 디코더에서 생성할 문장: "I go to school"
- 마지막 간다 부문에 입력 되었던 [0.7, 0.8, 0.9] 벡터를 하나의 고정된 컨텍스트 벡터로 이동
인코더 안에서 출력 되었던 컨텍스트 벡터 자체를 초기화 값으로 받아 출력 시퀀스를 생성
- 초기 히든 상태 \(s_0 = h_T = [0.7, 0.8, 0.9]\)
- 출력 시퀀스 : \(Y = [y_1, y_2, y_3, \dots, y_L]\)
스텝 별 계산
- 디코더 내에서 입력된 첫 단어 `I`에 대한 입력 벡터
- \(e_1 = [0.1, 0.2, 0.3]\)
- 입력 연결 \([s_0, e_1] = [0.7, 0.8, 0.9, 0.1, 0.2, 0.3]\)
선형 변환을 가중치 행렬과 바이어스 값 계산
$$
W (예제 값):
W = \begin{bmatrix}
0.1 & 0.2 & 0.3 \cr
0.4 & 0.5 & 0.6 \cr
0.7 & 0.8 & 0.9 \cr
0.1 & 0.3 & 0.5 \cr
0.2 & 0.4 & 0.6 \cr
0.3 & 0.7 & 0.8
\end{bmatrix}
$$
- 바이어스
- \(b = [0.01, 0.02, 0.03]\)
- 계산 결과
- \(z = [0.56, 0.78, 0.88]\)
- 비선형 활성화 함수:
- \(s_1 = \tanh(z)\)
- \(\tanh([0.56, 0.78, 0.88]) \approx [0.5, 0.65, 0.71]\)
- 최종 결과
- \(s_1 = [0.5, 0.65, 0.71]\)
이런 방식을 통해 디코더 내의 히든 스테이트를 생성 후, 나머지 단어들의 벡터 값을 이어가며 계산한 후 최종 출력값을 소프트맥스를 통해
상반되는 단어 I go to school 을 생성하게끔 만든다.
이미 인코더 및 디코더는 독립적인 개별 모델이므로, 입력과 출력의 길이가 달라도 상관 없다는 부분이 가장 큰 이점이나, 이는 문맥이 길어질수록 고정된 Context Vector를 통해 출력해야 하는 부분이 가장 큰 담점이기도 했습니다.
그로 인해 기존의 고질적인 문제를 해결하지 못하거나, 유의미한 학습이 불가능하다는 문제점에 봉착하게 되었는데. (압축하는 과정에서 발생되는 정보손실)
Attention의 등장
그림으로 이해하는 어텐션 & `Seq2Seq` 메커니즘

단순하게 설명하자면, 기존의 인코더-디코더 쌍향 방식은 디코더의 출력 계산 값에서 인코더의 마지막 값만을 담은 컨텍스트 벡터와, 디코더 첫 출력간의 계산에서만 진행되던 방식을
애초부터 인코더 단의 존재하던 은닉층들을 모두 비교하며 더하겠다는 소위 말하면 꼼꼼한 B사감 께서 등장하셔서 정해진 방에서 튀어나와 노는놈 잡겠다고 선포하는 것이나 다름이 없다는 개념으로 알아주시면 될 것 같습니다.
어텐션의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고한다는 점입니다. 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보게 됩니다.
주요 개념
1. 어텐션 함수
- \(Query\) : 무엇에 집중할지 정의하는 벡터
- \(t\) 시점의 디코더 셀에서의 은닉 상태
- \(Key\) : 입력 데이터의 특징 자체를 요약한 벡터
- 인코더에서 생성된 단어들의 히든 스테이트를 변환
- \(Values\) : 실제 정보가 담긴 벡터
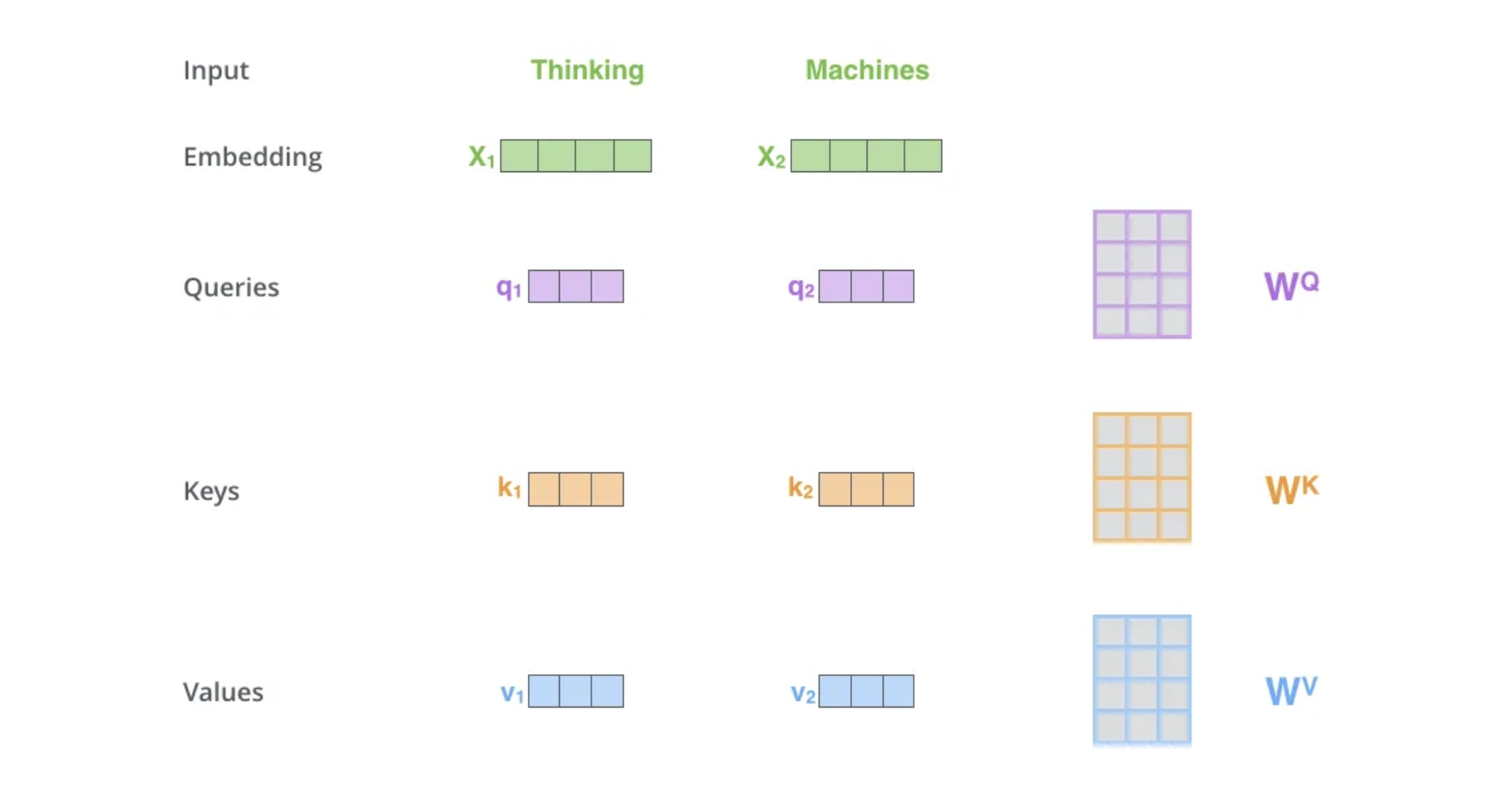
상기 그림들을 하나하나씩 뜯어 보자면
- Input:
- 입력 단어들(예: “Thinking”, “Machines”)이 나타나 있습니다.
- 각 단어는 임베딩(Embedding)으로 변환됩니다 \(x_1, x_2\)
- Query, Key, Value 벡터 생성:
입력 임베딩 \(x_1\), \(x_2\)는 각각 3개의 선형 변환(가중치 행렬 \((W^Q, W^K, W^V)\)을 통해 \(Query (q_1, q_2), Key (k_1, k_2), Value (v_1, v_2)\) 벡터로 변환됩니다.
- 변환 과정
\(Q = XW^Q, \quad K = XW^K, \quad V = XW^V\)
- Query, Key, Value의 목적:
\(Query (Q)\): “내가 어디에 집중해야 하는가?“를 정의합니다.
\(Key (K)\): “어떤 정보가 제공되는가?“를 정의합니다.
\(Value (V)\): “집중해야 할 실제 정보”를 제공합니다.
\(Attention(Q, K, V) = Attention Value\)
2. 어텐션 스코어
유사도 기반으로 Value 값을 얼마나 반영할 것인지를 결정하는 가중치 계산 방법
수식 : \(text{Attention Score} = q \cdot k^\top\)
\(q: Query\) 벡터(현재 디코더 상태)
\(k: Key\) 벡터(입력 단어의 정보)

예제 어제 피자를 먹고 싶었다라는 예제를 통해 현재 상태를 나타냄, 그렇게 표현된 입력 단어의 해당되는 정보 이 두가지를 행렬의 내적과 같은 의미로 계산하며 유사도 값을 산출해냅니다.
그리고 계산된 점곱(내적과 비슷하단 개인적 의견임) 결과를 Key의 차원 수의 제곱근으로 나눕니다.
수식 : \(\frac{Q \cdot K^T}{\sqrt{d_k}}\)
그렇게 나온 스케일링 된 점곱의 결과를 \(Softmax\)로 정규화 해서, 각 Key에 대한 가중치를 생성함
그 값이 바로 어텐션 스코어 입니다.
Key 값 More Deep
“피자를”, “먹고”, “싶었다” 라는 단어를 전제로 한 번 예시를 계산해보자면
1.1 Key는 입력 단어의 “특징 요약”
Key는 입력 시퀀스의 각 단어가 자신의 문맥 정보를 벡터로 변환한 결과입니다.
Key는 다음을 포함할 수 있습니다
1. 단어의 의미:
- 단어 자체가 가지고 있는 의미적 정보.
2. 문맥에서의 역할:
- 예: “피자를”은 목적어, “먹고”는 동사, “싶었다”는 감정을 나타내는 동사.
Key는 Query(현재 디코더 상태)가 “이 단어가 얼마나 중요한지”를 판단하기 위한 기준점 역할을 합니다.
- 디코더의 Query가 “현재 예측하려는 단어”에 대해 어떤 입력 단어에 집중할지 결정하려면, 각 입력 단어(Key)와 비교가 필요합니다
2. Key 값의 생성 과정
Key는 인코더에서 각 입력 단어를 처리하면서 생성됩니다.
구체적으로:
1. 단어 임베딩:
• 단어 “피자를”은 정수 인덱스(예: 12)로 시작하지만, 이를 고차원 벡터(예: [0.2, 0.8, 0.6])로 변환합니다.
2. 히든 스테이트:
• RNN/LSTM/Transformer와 같은 모델이 단어 임베딩과 이전 단어 정보를 결합하여 히든 스테이트를 생성합니다.
• 예: “피자를” → \(h_2 = [0.4, 0.5, 0.7]\)
3. Key 값으로 변환:
• 히든 스테이트를 Key 가중치 행렬 W_K로 변환하여 Key를 생성합니다:
\(k_i = W_K \cdot h_i\)
3. 예제: “피자를 먹고 싶었다”의 Key 값
문장 예제
문장: “피자를 먹고 싶었다”
• 입력 단어의 히든 스테이트:
• “피자를”: h_2 = [0.4, 0.5, 0.7]
• “먹고”: h_3 = [0.3, 0.6, 0.2]
• “싶었다”: h_4 = [0.9, 0.8, 0.1]
- Key 값 생성
- Key 값은 W_K를 사용하여 각 히든 스테이트를 변환합니다:
\(k_2 = W_K \cdot h_2, \quad k_3 = W_K \cdot h_3, \quad k_4 = W_K \cdot h_4\)
예:
- “피자를”: k_2 = [0.3, 0.7, 0.5]
- “먹고”: k_3 = [0.2, 0.8, 0.6]
- “싶었다”: k_4 = [0.6, 0.1, 0.9]
3. Value값 계산
각 입력 단어의 은닉층을 사용해서, Value를 생성하고 그에 따른 컨텍스트 벡터를 생성하는데 사용
수식
\(Context = c_t = \sum_{i=1}^T \alpha_{t,i} v_i\)
마지막. 디코더 값에 있는 t시점의 은닉층과 결합
- \(o_t = W_o \cdot [s_t, c_t] + b_o\)
- 디코더의 은닉 상태 \(s_t\)
- 컨텍스트 벡터 \(c_t\)
- \(o_t\) 디코더의 출력 로짓
- \(W_o\) 선형 변환 가중치
- \(b_o\) 편향 값
그렇게 계산 후, 최종 출력층으로 보내기 전, 마지막 계산을 거친다. 새로운 은닉층을 업데이트 하기 위해서인데, 학습 가능한 가중치 행렬과 컨텍스트 벡터, 그리고 새로운 디코더 상태를 하이퍼볼릭 탄젠트를 통해 계산해줍니다.
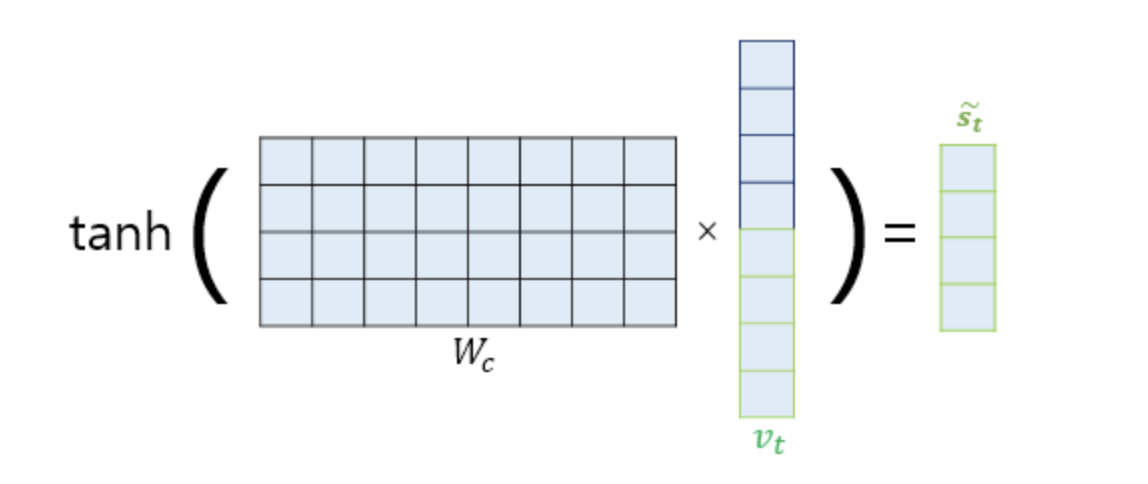
수식
\(\tilde{s}_t = \tanh(W_c \cdot [s_t; v_t])\)
- \(s_t\) : 디코더의 이전 히든 상태
- \(v_t\) : 컨텍스트 벡터의 벡터
- \(s_t; v_t;\) : 디코더 상태의 \(s_t\)와 컨텍스트 벡터 \(v_t\)의 연결
- \(W_c\) : 가중치 행렬
- \(tahn\): 하이퍼볼릭 탄젠트
디코더의 현재 상태에 어텐션 메커니즘이 결합된 벡터를 연결시킵니다.
결합된 입력 벡터에 선형 변환을 적용후에, 비선형 함수를 적용시키고, 그에 따라 새로운 은닉층을 업데이트 시킵니다.
그렇게 얻은 값을 기반으로 소프트맥스 함수로 확률 값을 내뱉으면 계산이 완료가 됩니다.
최종 수식
\(P(y_t = w_i | s_t, c_t) = \frac{\exp(o_{t, i})}{\sum_{j=1}^V \exp(o_{t, j})}\)
최종 요약
어텐션 메커니즘
- 어텐션은 인코더의 모든 히든 상태를 다시 참조하여 정보 손실 문제를 해결:
- 디코더가 매 시점에 출력 단어를 생성할 때, 인코더의 전체 입력 문장을 다시 참고.
- 입력 단어들 중 해당 시점에서 중요한 단어에 가중치를 더 높게 부여.
- Query (Q): 디코더의 현재 상태를 나타내며, “무엇에 집중해야 하는가?“를 결정.
- Key (K): 입력 데이터의 각 단어의 특징 벡터. “어떤 정보가 제공되는가?“를 정의.
- Value (V): Key와 관련된 실제 정보를 제공.
어텐션 계산 과정
1. 어텐션 스코어 계산 : \(\text{Score} = Q \cdot K^\top\)
점곱 결과를 Key의 차원 수로 스케일링 : \(\text{Scaled Score} = \frac{Q \cdot K^\top}{\sqrt{d_k}}\)
2. 컨텍스트 벡터 생성 : \(c_t = \sum_{i=1}^T \alpha_{t,i} v_i\)
3. 디코더와 결합 : \(\tilde{s}_t = \tanh(W_c \cdot [s_t; c_t])\)
4. 확률 계산 : \(P(y_t = w_i | s_t, c_t) = \frac{\exp(o_{t, i})}{\sum_{j=1}^V \exp(o_{t, j})}\)
'딥러닝, 논문 리뷰' 카테고리의 다른 글
| [딥러닝] 최적화와 경사하강법 Deep Dive(배치 경사하강법, 확률적 경사하강법) - 1 (0) | 2025.01.16 |
|---|---|
| [딥러닝] Attention Machanism 밑바닥부터 들어가기 - Deep Dive 2탄 (1) | 2025.01.14 |
| [딥러닝 논문리뷰] Seq2Seq 메커니즘 Sequence - 2 (1) | 2025.01.10 |
| [딥러닝, 논문리뷰] Meta - Memory Layers at Scale (0) | 2025.01.04 |
| [딥러닝, 논문리뷰] 엘모(Embeddings from Language Model, ELMo) (1) | 2025.01.02 |